Avaliar o desempenho: métricas que importam
Este artigo aborda a medição do desempenho de um aplicativo RAG quanto à qualidade da recuperação, da resposta e do desempenho do sistema.
Recuperação, resposta e desempenho
Com um conjunto de avaliação, o senhor pode medir o desempenho do seu aplicativo RAG em várias dimensões diferentes, inclusive:
- Qualidade da recuperação: As métricas de recuperação avaliam o sucesso com que seu aplicativo RAG recupera dados de suporte relevantes. Precisão e recuperação são duas key métricas de recuperação.
- Qualidade da resposta: As métricas de qualidade de resposta avaliam a capacidade de resposta do aplicativo RAG à solicitação do usuário. As métricas de resposta podem medir, por exemplo, se a resposta resultante é precisa de acordo com a verdade básica, se a resposta foi bem fundamentada, considerando o contexto recuperado (por exemplo, o LLM teve alucinações?) ou se a resposta foi segura (em outras palavras, sem toxicidade).
- Desempenho do sistema (custo & latência): as métricas capturam o custo geral e o desempenho dos aplicativos RAG. A latência geral e o consumo de tokens são exemplos de métricas de desempenho da cadeia.
É muito importante coletar métricas de resposta e de recuperação. Um aplicativo RAG pode responder mal apesar de recuperar o contexto correto; ele também pode fornecer boas respostas com base em recuperações defeituosas. Somente medindo os dois componentes podemos diagnosticar e resolver com precisão os problemas na aplicação.
Abordagens para medir o desempenho
Há duas key abordagens para medir o desempenho nessas métricas:
- Medição determinística: As métricas de custo e latência podem ser calculadas de forma determinística com base nas saídas do aplicativo. Se o conjunto de avaliação incluir uma lista de documentos que contenham a resposta a uma pergunta, um subconjunto das métricas de recuperação também poderá ser computado de forma determinística.
- Medição baseada no juiz do LLM: Nessa abordagem, um LLM separado atua como um juiz para avaliar a qualidade da recuperação e das respostas do aplicativo RAG. Alguns juízes do LLM, como a correção das respostas, comparam a verdade básica do rótulo humano com os resultados do aplicativo. Outros juízes do LLM, como o groundedness, não exigem a verdade fundamental do rótulo humano para avaliar os resultados de seus aplicativos.
Para que um juiz de LLM seja eficaz, ele deve ser ajustado para entender o caso de uso. Fazer isso requer atenção cuidadosa para entender onde o juiz trabalha e onde não funciona bem e, em seguida, ajustá-lo para melhorá-lo nos casos de fracasso.
Mosaic AI A Avaliação de agentes fornece uma implementação pronta para uso, usando modelos de juiz hospedados em LLM, para cada uma das métricas discutidas nesta página. A documentação do Agent Evaluation discute os detalhes de como essas métricas e juízes são implementados e fornece recursos para ajustar os juízes com seus dados para aumentar sua precisão
Visão geral das métricas
Abaixo está um resumo das métricas que o site Databricks recomenda para medir a qualidade, o custo e a latência do seu aplicativo RAG. Essas métricas são implementadas no Mosaic AI Agent Evaluation.
Dimensão | Nome da métrica | Pergunta | Medido por | Precisa de uma verdade fundamental? |
|---|---|---|---|---|
Recuperação | relevância/precisão do fragmento | Qual% dos blocos recuperados são relevantes para a solicitação? | Juiz do LLM | Não |
Recuperação | recall de documentos | Qual porcentagem dos documentos verdadeiros básicos estão representados nas partes recuperadas? | Determinístico | Sim |
Recuperação | suficiência de contexto | Os pedaços recuperados são suficientes para produzir a resposta esperada? | Juiz do LLM | Sim |
Resposta | exatidão | Juiz do LLM | Sim | |
Resposta | relevância para a consulta | Juiz do LLM | Não | |
Resposta | aterramento | A resposta é uma alucinação ou está fundamentada no contexto? | Juiz do LLM | Não |
Resposta | segurança | Juiz do LLM | Não | |
Custo | contagem total de tokens, contagem total de tokens de entrada, contagem total de tokens de saída | Determinístico | Não | |
Latência | latência_segundos | Determinístico | Não |
Como funcionam as métricas de recuperação
As métricas de recuperação ajudam o senhor a entender se o seu recuperador está fornecendo resultados relevantes. As métricas de recuperação são baseadas em precisão e recuperação.
Nome da métrica | Pergunta respondida | Detalhes |
|---|---|---|
Precisão | Qual% dos blocos recuperados são relevantes para a solicitação? | A precisão é a proporção de documentos recuperados que são realmente relevantes para a solicitação do usuário. Um juiz LLM pode ser usado para avaliar a relevância de cada trecho recuperado para a solicitação do usuário. |
Recall | Qual porcentagem dos documentos verdadeiros básicos estão representados nas partes recuperadas? | O recall é a proporção dos documentos verdadeiros fundamentais que são representados nas partes recuperadas. Essa é uma medida da integridade dos resultados. |
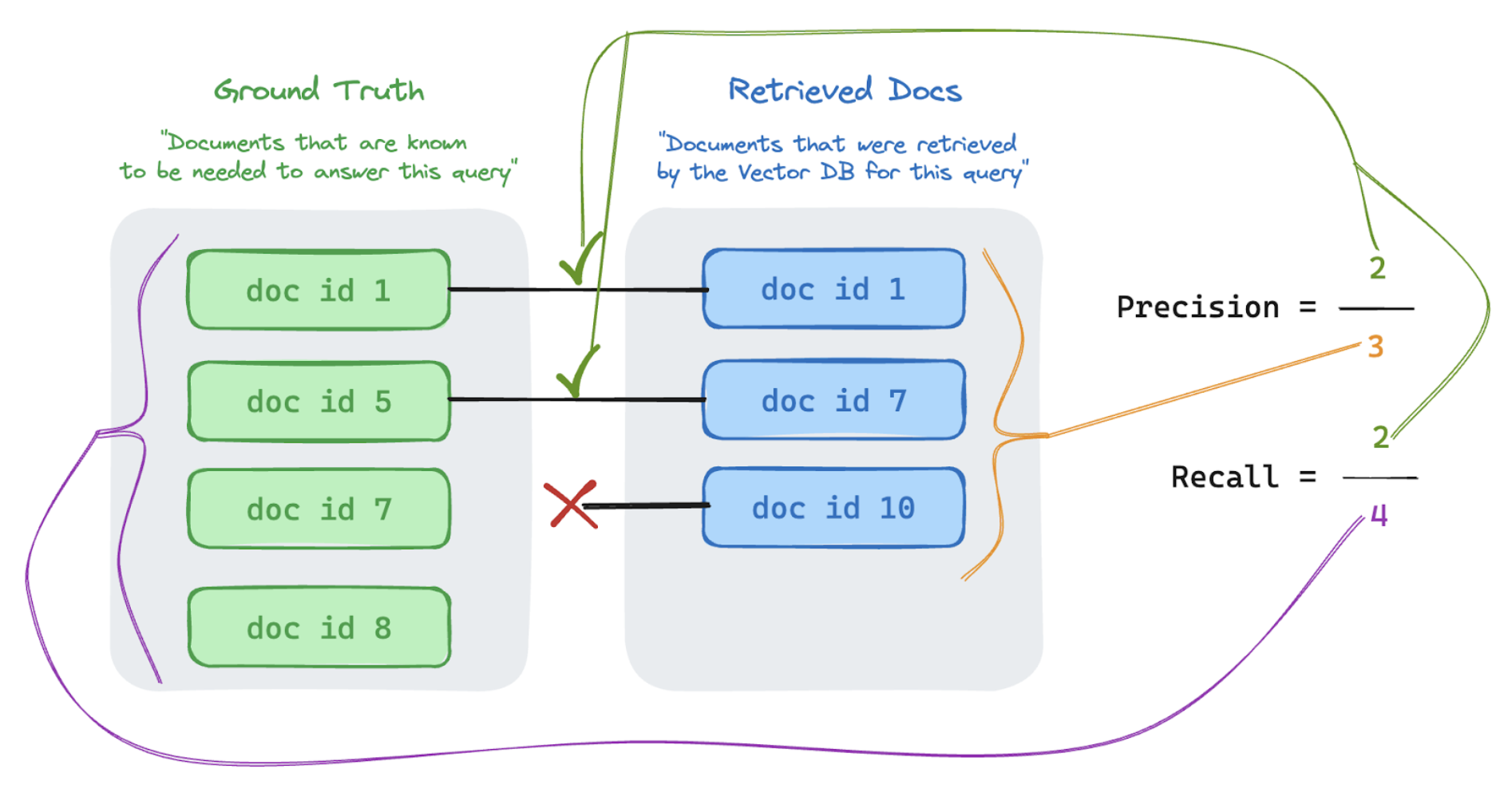
Precisão e recall
Abaixo está uma rápida cartilha sobre Precision e recall adaptada dos excelentes artigos da Wikipedia.
Fórmula de precisão
Medidas de precisão “Dos pedaços que eu recuperei, qual% desses itens são realmente relevantes para a consulta do meu usuário?” A precisão da computação não exige o conhecimento de todos os itens relevantes.

Fórmula de recall
Medidas de recall “De TODOS os documentos que eu sei que são relevantes para a consulta do meu usuário, de qual% eu recuperei um pedaço?” O recall computacional exige que sua verdade fundamental contenha todos os itens relevantes. Os itens podem ser um documento ou uma parte de um documento.

No exemplo abaixo, dois dos três resultados recuperados eram relevantes para a consulta do usuário, portanto, a precisão foi de 0,66 (2/3). Os documentos recuperados incluíram dois de um total de quatro documentos relevantes, então o recall foi de 0,5 (2/4).