Google BigQuery
この記事では、Databricks で Google BigQuery テーブルの読み取りと書き込みを行う方法について説明します。
実験段階
従来のクエリ フェデレーションのドキュメントは廃止されており、更新されない可能性があります。このコンテンツに記載されている構成は、Databricks によって公式に承認またはテストされたものではありません。レイクハウスフェデレーションがソースデータベースをサポートしている場合、Databricks代わりにそれを使用することをお勧めします。
BigQuery には、キーベースの認証を使用して接続する必要があります。
権限
プロジェクトには、BigQuery を使用して読み取りと書き込みを行うための特定の Google 権限が必要です。
この記事では BigQuery マテリアライズドビューについて説明します。 詳細については、Google の記事「 マテリアライズドビューの概要」を参照してください。その他の BigQuery の用語と BigQuery のセキュリティモデルについては、 Google BigQuery のドキュメントをご覧ください。
BigQuery でのデータの読み取りと書き込みは、次の 2 つの Google Cloud プロジェクトに依存します。
- プロジェクト (
project): Databricks が BigQuery テーブルを読み書きする元の Google Cloud プロジェクトの ID。 - 親プロジェクト (
parentProject): 親プロジェクトの ID で、読み取りと書き込みに対して課金する Google Cloud プロジェクト ID。 これを、キーを生成する Google サービス アカウントに関連付けられている Google Cloud プロジェクトに設定します。
BigQuery にアクセスするコードでは、 project と parentProject の値を明示的に指定する必要があります。次のようなコードを使用します。
spark.read.format("bigquery") \
.option("table", table) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
Google Cloud プロジェクトに必要な権限は、 project と parentProject が同じかどうかによって異なります。 次のセクションでは、各シナリオに必要なアクセス許可を示します。
project と parentProject が一致する場合に必要なアクセス許可
projectとparentProjectの ID が同じ場合は、次の表を使用して最小限のアクセス許可を決定します。
Databricks タスク | プロジェクトに必要な Google の権限 |
|---|---|
マテリアライズドビューを使用せずに BigQuery テーブルを読み取る |
|
BigQueryマテリアライズドビューで テーブルを読み取る |
マテリアライズプロジェクトでは、
|
BigQuery テーブルを作成する |
|
projectとparentProjectが異なる場合に必要な権限
projectとparentProjectの ID が異なる場合は、次の表を使用して最小限のアクセス許可を決定します。
Databricks タスク | Google の権限が必要 |
|---|---|
マテリアライズドビューを使用せずに BigQuery テーブルを読み取る |
|
BigQueryマテリアライズドビューで テーブルを読み取る |
マテリアライズプロジェクトでは、
|
BigQuery テーブルを作成する |
|
ステップ 1: Google Cloud を設定する
BigQuery Storage API を有効にする
BigQuery Storage API は、BigQuery が有効になっている新しい Google Cloud プロジェクトではデフォルトで有効になっています。ただし、既存のプロジェクトがあり、BigQuery Storage API が有効になっていない場合は、このセクションの手順に従って有効にします。
BigQuery Storage API は、Google Cloud CLI または Google Cloud Console を使用して有効にできます。
Google Cloud CLI を使用して BigQuery Storage API を有効にする
gcloud services enable bigquerystorage.googleapis.com
Google Cloud Console を使用して BigQuery Storage API を有効にする
-
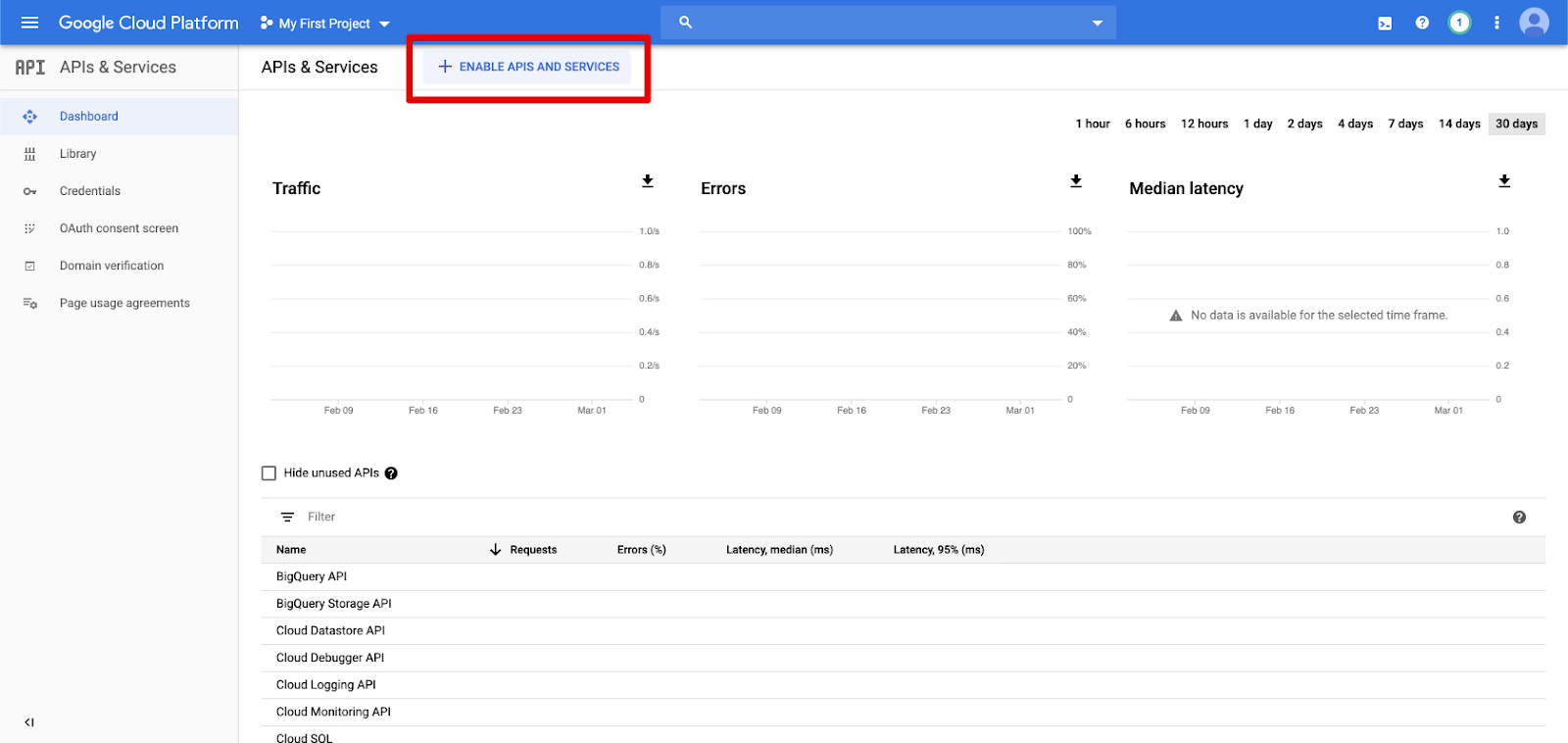
左側のナビゲーション ウィンドウで [API & サービス ] をクリックします。
-
[ENABLE APIS AND サービス ] ボタンをクリックします。
-
検索バーに「
bigquery storage api」と入力し、最初の結果を選択します。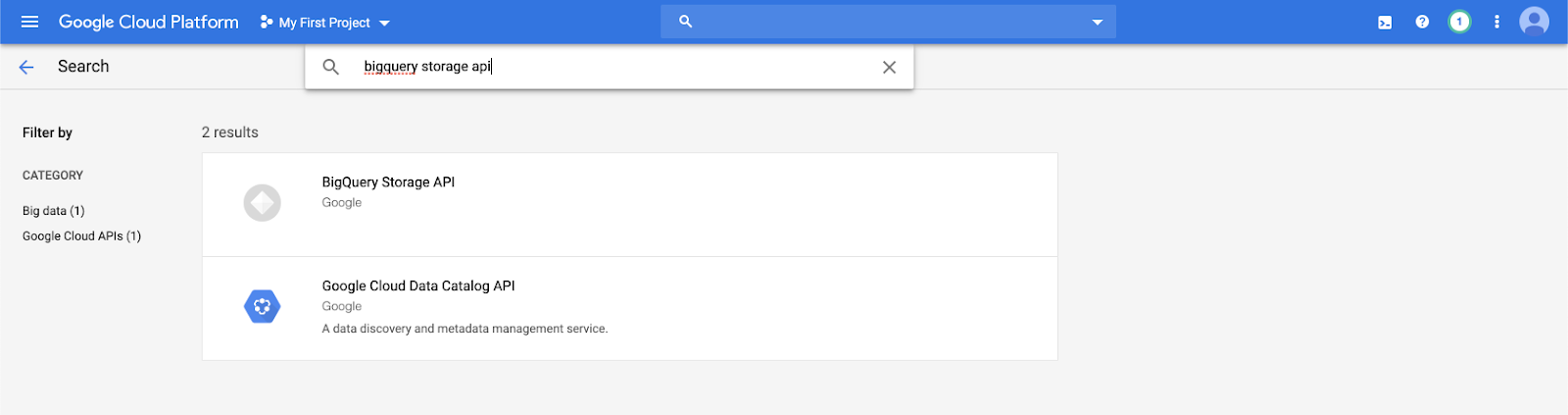
-
BigQuery Storage API が有効になっていることを確認します。
Databricks の Google サービス アカウントを作成する
Databricks クラスター用のサービス アカウントを作成します。Databricks では、このサービス アカウントに、タスクを実行するために必要な最小限の特権を付与することをお勧めします。 BigQuery のロールと権限をご覧ください。
サービスアカウントは、Google Cloud CLI または Google Cloud コンソールを使用して作成できます。
Google Cloud CLI を使用して Google サービス アカウントを作成する
gcloud iam service-accounts create <service-account-name>
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.user \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.dataEditor \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
サービスアカウントのキーを作成します。
gcloud iam service-accounts keys create --iam-account \
"<service-account-name>@<project-name>.iam.gserviceaccount.com" \
<project-name>-xxxxxxxxxxx.json
Google Cloud Console を使用して Google サービス アカウントを作成する
アカウントを作成するには:
-
左側のナビゲーション・ペインで「 IAMおよび管理 」をクリックします。
-
「サービスアカウント」 をクリックします。
-
[+ CREATE サービス アカウント ] をクリックします。
-
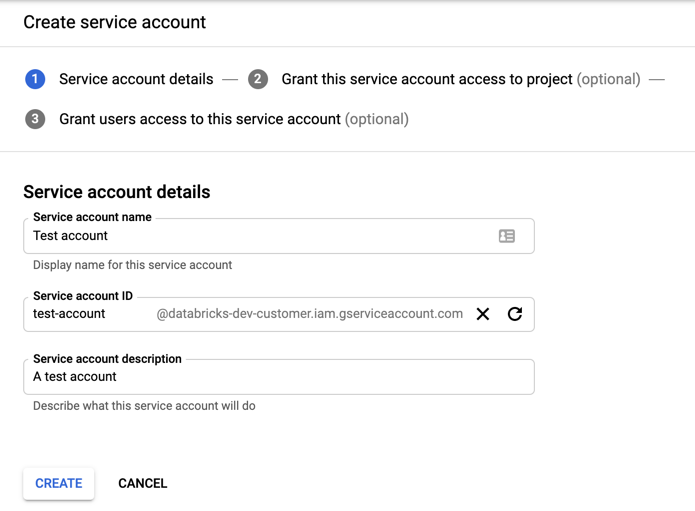
サービスアカウントの名前と説明を入力します。
-
[ 作成 ]をクリックします。
-
サービスアカウントの役割を指定します。[ ロールの選択 ] ドロップダウンに「
BigQuery」と入力し、次のロールを追加します。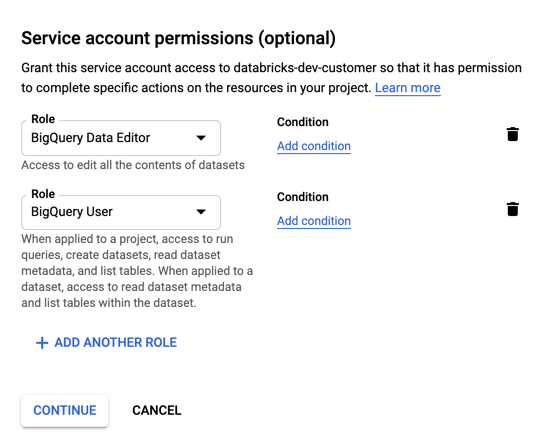
-
「 続行 」をクリックします。
-
[ 完了] をクリックします。
サービスアカウントのキーを作成するには:
-
[サービス アカウント] の一覧で、新しく作成したアカウントをクリックします。
-
[キー] セクションで、[ キーの追加] > [新しいキーの作成 ] ボタンを選択します。
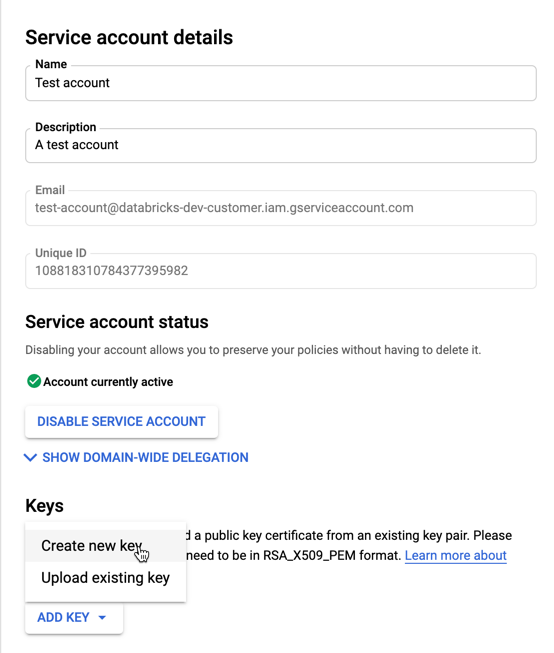
-
JSON キータイプを受け入れます。
-
[作成 ] をクリックします。JSONキーファイルがコンピューターにダウンロードされます。
サービス アカウント用に生成する JSON キー ファイルは、Google Cloud アカウントのデータセットとリソースへのアクセスを制御するため、許可されたユーザーとのみ共有する必要がある秘密鍵です。
一時ストレージ用の Google Cloud Storage (GCS) バケットを作成する
BigQuery にデータを書き込むには、データソースが GCS バケットにアクセスできる必要があります。
-
左側のナビゲーション ウィンドウで [ストレージ ] をクリックします。
-
「 バケットを作成 」をクリックします。
-
バケットの詳細を設定します。
-
[ 作成 ]をクリックします。
-
[権限 ] タブをクリックし、[ メンバーの追加] をクリックします。
-
バケットのサービスアカウントに次のアクセス許可を付与します。
-
[ 保存 ]をクリックします。
ステップ 2: Databricks を設定する
BigQueryテーブルにアクセスするようにクラスターを設定するには、JSONキーファイルをSpark設定として指定する必要があります。ローカルツールを使用して、JSONキーファイルをBase64エンコードします。 セキュリティ上の理由から、キーにアクセスできる可能性のあるWebベースまたはリモートツールを使用しないでください。
[ Spark Config ] タブで、次の Spark 設定を追加します。<base64-keys> を Base64 でエンコードされた JSON キーファイルの文字列に置き換えます。括弧内の他の項目 ( <client-email>など) を、JSON キーファイルのフィールドの値に置き換えます。
credentials <base64-keys>
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key <private-key>
spark.hadoop.fs.gs.auth.service.account.private.key.id <private-key-id>
BigQuery テーブルの読み取りと書き込み
BigQuery テーブルを読み取るには、次のように指定します
df = spark.read.format("bigquery") \
.option("table",<table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
BigQuery テーブルに書き込むには、次のように指定します。
df.write.format("bigquery") \
.mode("<mode>") \
.option("temporaryGcsBucket", "<bucket-name>") \
.option("table", <table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.save()
ここで、 <bucket-name> は 、一時ストレージ用の Google Cloud Storage (GCS) バケットを作成するで作成したバケットの名前です。<project-id> と <parent-id> の値の要件については、権限を参照してください。
BigQuery から外部テーブルを作成する
この機能は Unity Catalog ではサポートされていません。
Databricksでアンマネージドテーブルを宣言して、BigQueryから直接データを読み取ることができます。
CREATE TABLE chosen_dataset.test_table
USING bigquery
OPTIONS (
parentProject 'gcp-parent-project-id',
project 'gcp-project-id',
temporaryGcsBucket 'some-gcp-bucket',
materializationDataset 'some-bigquery-dataset',
table 'some-bigquery-dataset.table-to-copy'
)
Python ノートブックの例: Google BigQuery テーブルを データフレーム に読み込む
次の Python ノートブックは、Google BigQuery テーブルを Databricks データフレーム に読み込みます。
Google BigQuery Python サンプル ノートブック
Scala ノートブックの例: Google BigQuery テーブルを データフレーム に読み込む
次の Scala ノートブックは、Google BigQuery テーブルを Databricks データフレーム に読み込みます。