AWS Glue データカタログをメタストアとして使用する (レガシ)
このドキュメントは廃止されており、更新されない可能性があります。
外部メタストアの使用は、従来のデータガバナンス モデルです。 Databricks では、Unity Catalog にアップグレードすることをお勧めします。 Unity Catalog は、アカウント内の複数のワークスペースにわたるデータアクセスを一元的に管理および監査するための場所を提供することで、データのセキュリティとガバナンスを簡素化します。 「Unity Catalog とは」を参照してください。
Databricks RuntimeAWSGlueデータカタログをメタストアとして使用するように を構成できます。これは、 Hive metastoreのドロップイン代替品として機能します。
各 AWS アカウント は、カタログ ID が AWS アカウント ID と同じ AWS リージョンに 1 つのカタログを所有します。 Glue Catalog を Databricks のメタストアとして使用すると、AWS のサービス、アプリケーション、または AWS アカウント間で共有メタストアを有効にできる可能性があります。
複数の Databricks ワークスペースを構成して、同じメタストアを共有できます。
この記事では、インスタンスプロファイルを使用して でGlue データカタログに安全にアクセスする方法について説明します。Databricks
必要条件
- がデプロイされている アカウントと AWSIAMデータカタログを含む アカウント内のロールとポリシーAWSDatabricks AWS管理者アクセス権が必要です。Glue
- GlueデータカタログがデプロイされているAWS アカウントと異なる アカウントにある場合、Databricksクロスアカウント アクセス ポリシー では、 デプロイされている アカウントからカタログへのアクセスを許可する必要があります。AWSDatabricksクロスアカウントアクセスの付与は、Glue のリソースポリシーを使用したもののみサポートしていることに注意してください。
- 組み込みモードには、Databricks Runtime 8.4 以降、または Databricks Runtime 7.3 LTS が必要です。
Glue データカタログをメタストアとして構成する
Glue カタログの統合を有効にするには、 Spark 構成を spark.databricks.hive.metastore.glueCatalog.enabled trueに設定します。 この設定は、デフォルトでは無効になっています。 つまり、デフォルトは、 Databricks ホストされた Hive metastoreを使用するか、構成されている場合は他の外部メタストアを使用することです。
対話型クラスターまたはジョブ クラスターの場合は 、クラスターを開始する前に 、クラスター構成で構成を設定します。
この構成オプションは、稼働中のクラスターでは変更 できません 。
spark-submitジョブを実行するときは、spark-submit パラメーターで --conf spark.databricks.hive.metastore.glueCatalog.enabled=true を使用してこの構成オプションを設定するか、SparkSession または SparkContextを作成する 前に コードで設定します。例えば:
from pyspark.sql import SparkSession
# Set the Glue confs here directly instead of using the --conf option in spark-submit
spark = SparkSession.builder. \
appName("ExamplePySparkSubmitTask"). \
config("spark.databricks.hive.metastore.glueCatalog.enabled", "true"). \
enableHiveSupport(). \
getOrCreate()
print(spark.sparkContext.getConf().get("spark.databricks.hive.metastore.glueCatalog.enabled"))
spark.sql("show databases").show()
spark.stop()
Glueカタログへのアクセスを設定する方法は、DatabricksとGlueカタログが同じAWSアカウントとリージョンにあるか、異なるアカウントにあるか、または異なるリージョンにあるかによって異なります。この記事の残りの部分で適切な手順に従います。
- 同じ AWS アカウントとリージョン : ステップ 1 に従い、次にステップ 3 から 5 に従います。
- クロスアカウント : ステップ 1 から 6 に従います。
- クロスリージョン : ステップ 1 に従い、次にステップ 3 から 6 に従います。
AWS Glue データカタログ ポリシー は、メタデータへのアクセス許可のみを定義します。S3 ポリシーは、コンテンツ自体へのアクセス権限を定義します。 これらの手順では、 AWS Glue データカタログにポリシーを設定します。 関連する S3 バケットまたはオブジェクトレベルのポリシーは設定 されません 。 の 権限を設定するための チュートリアル:S3 インスタンスプロファイルを使用して アクセスを設定する を参照してください。S3Databricks
詳細については、「AWSGlueリソースレベルのIAM 権限とリソースベースのポリシーを使用して データカタログへのアクセスを制限する」を参照してください 。
ステップ1: Glue データカタログにアクセスするためのインスタンスプロファイルを作成する
-
AWS コンソールで、IAM サービスに移動します。
-
サイドバーの「ロール」タブをクリックします。
-
「 ロールの作成 」をクリックします。
-
[信頼されたエンティティのタイプを選択] で、[ AWS サービス ] を選択します。
-
EC2 サービスをクリックします。
-
[Use case (ユースケースの選択)] で、[ EC2 ] をクリックします。
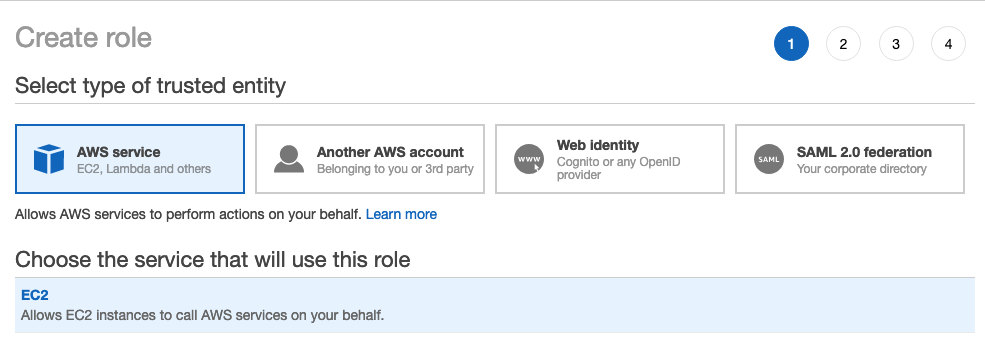
-
「 次へ: 権限」 をクリックし、「 次へ: 確認」 をクリックします。
-
[ロール名] フィールドに、ロール名を入力します。
-
「 ロールの作成 」をクリックします。ロールのリストが表示されます。
-
-
ロールの一覧で、ロールをクリックします。
-
インライン ポリシーを Glue カタログに追加します。
-
[アクセス許可] タブで、[
 ] をクリックします。
] をクリックします。 -
[JSON ] タブをクリックします。
-
このポリシーをコピーしてタブに貼り付けます。
JSON{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "GrantCatalogAccessToGlue",
"Effect": "Allow",
"Action": [
"glue:BatchCreatePartition",
"glue:BatchDeletePartition",
"glue:BatchGetPartition",
"glue:CreateDatabase",
"glue:CreateTable",
"glue:CreateUserDefinedFunction",
"glue:DeleteDatabase",
"glue:DeletePartition",
"glue:DeleteTable",
"glue:DeleteUserDefinedFunction",
"glue:GetDatabase",
"glue:GetDatabases",
"glue:GetPartition",
"glue:GetPartitions",
"glue:GetTable",
"glue:GetTables",
"glue:GetUserDefinedFunction",
"glue:GetUserDefinedFunctions",
"glue:UpdateDatabase",
"glue:UpdatePartition",
"glue:UpdateTable",
"glue:UpdateUserDefinedFunction"
],
"Resource": "arn:aws:glue:<aws-region-target-glue-catalog>:<aws-account-id-target-glue-catalog>:*",
"Condition": {
"ArnEquals": {
"aws:PrincipalArn": ["arn:aws:iam::<aws-account-id-databricks>:role/<iam-role-for-glue-access>"]
}
}
}
]
}
-
許可されるリソース (カタログ、データベース、テーブル、userDefinedFunction) の詳細な設定については、AWS GlueリソースARNsの指定を参照してください。
上記のポリシーで許可されているアクションの一覧が不十分な場合は、エラー情報を Databricks サポートに問い合わせてください。 最も簡単な回避策は、Glue へのフル アクセスを許可するポリシーを使用することです。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "GrantFullAccessToGlue",
"Effect": "Allow",
"Action": ["glue:*"],
"Resource": "*"
}
]
}
ステップ 2: ターゲットの Glue Catalog のポリシーを作成する
この手順は、ターゲットの Glue Catalog が Databricks のデプロイに使用されたもの とは異なる AWS アカウント にある場合にのみ実行してください。
-
AWS対象の カタログの アカウントにログインし、Glue Glueコンソールに移動します。
-
[設定] で、次のポリシーを [アクセス許可] ボックスに貼り付けます。 ステップ1から
<iam-role-for-glue-access>``<aws-account-id-databricks>、<aws-region-target-glue-catalog>、<aws-account-id-target-glue-catalog>、それに応じて設定します。JSON{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Example permission",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<aws-account-id-databricks>:role/<iam-role-for-glue-access>"
},
"Action": [
"glue:BatchCreatePartition",
"glue:BatchDeletePartition",
"glue:BatchGetPartition",
"glue:CreateDatabase",
"glue:CreateTable",
"glue:CreateUserDefinedFunction",
"glue:DeleteDatabase",
"glue:DeletePartition",
"glue:DeleteTable",
"glue:DeleteUserDefinedFunction",
"glue:GetDatabase",
"glue:GetDatabases",
"glue:GetPartition",
"glue:GetPartitions",
"glue:GetTable",
"glue:GetTables",
"glue:GetUserDefinedFunction",
"glue:GetUserDefinedFunctions",
"glue:UpdateDatabase",
"glue:UpdatePartition",
"glue:UpdateTable",
"glue:UpdateUserDefinedFunction"
],
"Resource": "arn:aws:glue:<aws-region-target-glue-catalog>:<aws-account-id-target-glue-catalog>:*"
}
]
}
手順 3: デプロイの作成に使用されたIAM ロールを検索するDatabricks
この IAMロールは、 Databricks アカウントの設定時に使用したロールです。
次の手順は、 プラットフォームの E2 バージョンの アカウントと別のバージョンの Databricks プラットフォームのアカウントでは異なります すべての新しい Databricks アカウントとほとんどの既存のアカウントは E2 になりました。
E2アカウントの場合:
-
アカウント所有者またはアカウント管理者として、 アカウントコンソールにログインします。
-
[ワークスペース] に移動し、ワークスペース名をクリックします。
-
[資格情報] ボックスで、[ロールARN]の末尾にあるロール名を書き留めます。
たとえば、ロール ARN
arn:aws:iam::123456789123:role/finance-prodでは、finance-prod がロール名です。
E2アカウントをご利用でない場合:
-
アカウント所有者として、 アカウントコンソールにログインします。
-
[AWS アカウント ] タブをクリックします。
-
ロール ARN の末尾にあるロール名 (ここでは testco-role ) をメモします。
ステップ 4: Glue Catalog インスタンスプロファイルを EC2 ポリシーに追加する
-
AWS コンソールで、IAM サービスに移動します。
-
サイドバーの「 ロール 」タブをクリックします。
-
ステップ 3 でメモしたロールをクリックします。
-
[アクセス許可] タブで、ポリシーをクリックします。
-
[ポリシーの編集] をクリックします。
-
ポリシーDatabricks を変更して、ステップ 1 で作成したインスタンスプロファイルをEC2 Sparkクラスターの インスタンスに 渡せるようにします。新しいポリシーがどのように見えるべきかの例を次に示します。
<iam-role-for-glue-access>をステップ 1 で作成したロールに置き換えます。-
プラットフォームの E2 バージョンのアカウントの場合:
JSON{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1403287045000",
"Effect": "Allow",
"Action": [
"ec2:AssociateDhcpOptions",
"ec2:AssociateIamInstanceProfile",
"ec2:AssociateRouteTable",
"ec2:AttachInternetGateway",
"ec2:AttachVolume",
"ec2:AuthorizeSecurityGroupEgress",
"ec2:AuthorizeSecurityGroupIngress",
"ec2:CancelSpotInstanceRequests",
"ec2:CreateDhcpOptions",
"ec2:CreateInternetGateway",
"ec2:CreatePlacementGroup",
"ec2:CreateRoute",
"ec2:CreateSecurityGroup",
"ec2:CreateSubnet",
"ec2:CreateTags",
"ec2:CreateVolume",
"ec2:CreateVpc",
"ec2:CreateVpcPeeringConnection",
"ec2:DeleteInternetGateway",
"ec2:DeletePlacementGroup",
"ec2:DeleteRoute",
"ec2:DeleteRouteTable",
"ec2:DeleteSecurityGroup",
"ec2:DeleteSubnet",
"ec2:DeleteTags",
"ec2:DeleteVolume",
"ec2:DeleteVpc",
"ec2:DescribeAvailabilityZones",
"ec2:DescribeIamInstanceProfileAssociations",
"ec2:DescribeInstanceStatus",
"ec2:DescribeInstances",
"ec2:DescribePlacementGroups",
"ec2:DescribePrefixLists",
"ec2:DescribeReservedInstancesOfferings",
"ec2:DescribeRouteTables",
"ec2:DescribeSecurityGroups",
"ec2:DescribeSpotInstanceRequests",
"ec2:DescribeSpotPriceHistory",
"ec2:DescribeSubnets",
"ec2:DescribeVolumes",
"ec2:DescribeVpcs",
"ec2:DetachInternetGateway",
"ec2:DisassociateIamInstanceProfile",
"ec2:ModifyVpcAttribute",
"ec2:ReplaceIamInstanceProfileAssociation",
"ec2:RequestSpotInstances",
"ec2:RevokeSecurityGroupEgress",
"ec2:RevokeSecurityGroupIngress",
"ec2:RunInstances",
"ec2:TerminateInstances"
],
"Resource": ["*"]
},
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::<aws-account-id-databricks>:role/<iam-role-for-glue-access>"
}
]
}- プラットフォームの他のバージョンのアカウントの場合:
JSON{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1403287045000",
"Effect": "Allow",
"Action": [
"ec2:AssociateDhcpOptions",
"ec2:AssociateIamInstanceProfile",
"ec2:AssociateRouteTable",
"ec2:AttachInternetGateway",
"ec2:AttachVolume",
"ec2:AuthorizeSecurityGroupEgress",
"ec2:AuthorizeSecurityGroupIngress",
"ec2:CancelSpotInstanceRequests",
"ec2:CreateDhcpOptions",
"ec2:CreateInternetGateway",
"ec2:CreateKeyPair",
"ec2:CreateRoute",
"ec2:CreateSecurityGroup",
"ec2:CreateSubnet",
"ec2:CreateTags",
"ec2:CreateVolume",
"ec2:CreateVpc",
"ec2:CreateVpcPeeringConnection",
"ec2:DeleteInternetGateway",
"ec2:DeleteKeyPair",
"ec2:DeleteRoute",
"ec2:DeleteRouteTable",
"ec2:DeleteSecurityGroup",
"ec2:DeleteSubnet",
"ec2:DeleteTags",
"ec2:DeleteVolume",
"ec2:DeleteVpc",
"ec2:DescribeAvailabilityZones",
"ec2:DescribeIamInstanceProfileAssociations",
"ec2:DescribeInstanceStatus",
"ec2:DescribeInstances",
"ec2:DescribePrefixLists",
"ec2:DescribeReservedInstancesOfferings",
"ec2:DescribeRouteTables",
"ec2:DescribeSecurityGroups",
"ec2:DescribeSpotInstanceRequests",
"ec2:DescribeSpotPriceHistory",
"ec2:DescribeSubnets",
"ec2:DescribeVolumes",
"ec2:DescribeVpcs",
"ec2:DetachInternetGateway",
"ec2:DisassociateIamInstanceProfile",
"ec2:ModifyVpcAttribute",
"ec2:ReplaceIamInstanceProfileAssociation",
"ec2:RequestSpotInstances",
"ec2:RevokeSecurityGroupEgress",
"ec2:RevokeSecurityGroupIngress",
"ec2:RunInstances",
"ec2:TerminateInstances"
],
"Resource": ["*"]
},
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::<aws-account-id-databricks>:role/<iam-role-for-glue-access>"
}
]
}
-
-
「 ポリシーの確認 」をクリックします。
-
[変更を保存] をクリックします。
ステップ 5: Glue Catalog インスタンスプロファイルを Databricks ワークスペースに追加する
-
管理者設定ページに移動します。
-
[ インスタンスプロファイル ] タブをクリックします。
-
[ インスタンスプロファイルの追加 ]ボタンをクリックします。 ダイアログが表示されます。
-
ステップ 1 のインスタンスプロファイル ARN を貼り付けます。
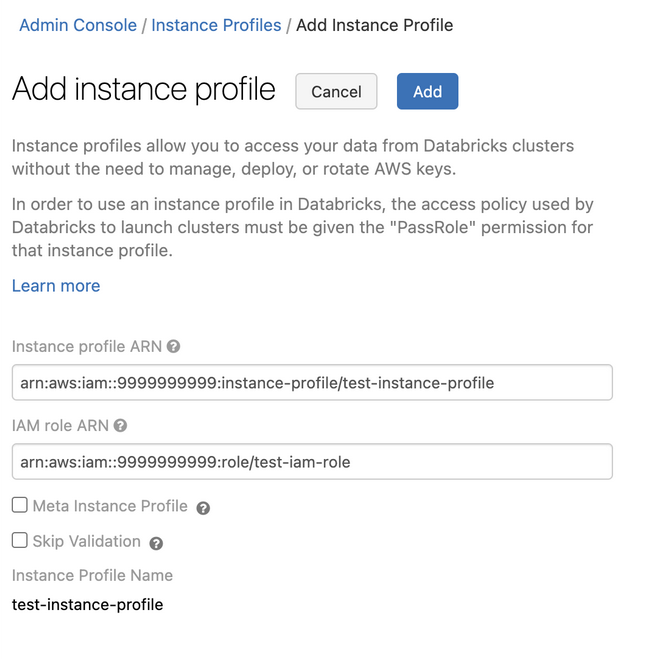
Databricks は、このインスタンスプロファイル ARN が構文的にも意味的にも正しいことを検証します。 セマンティックの正確性を検証するために、 Databricks は、このインスタンスプロファイルを使用してクラスターを起動してドライ実行を行います。 このドライ実行でエラーが発生すると、UI で検証エラーが発生します。
インスタンスプロファイルにタグ適用ポリシーが含まれている場合、インスタンスプロファイルの検証は失敗し、正当なインスタンスプロファイルを追加できなくなる可能性があります。 検証が失敗し、インスタンスプロファイルを Databricksに追加する場合は、インスタンスプロファイル API を使用して skip_validation を指定します。
-
[ 追加 ] をクリックします。
-
オプションで、インスタンスプロファイルを使用してクラスターを起動できるユーザーを指定します。
ステップ 6: Glue Catalog インスタンスプロファイルを使用してクラスターを起動する
-
クラスターを作成します。
-
クラスター作成ページの 「インスタンス 」タブをクリックします。
-
インスタンスプロファイル ドロップダウンリストで、インスタンスプロファイルを選択します。
-
ノートブックで次のコマンドを使用して、Glue カタログにアクセスできることを確認します。
SQLshow databases;コマンドが成功すると、この Databricks Runtime クラスターは Glueを使用するように設定されます。 AWS アカウントと Glue リージョンによっては、さらに 2 つのステップを実行する必要がある場合があります。
-
デプロイメントの AWSアカウントとDatabricks AWSデータカタログの アカウントが異なる場合は、追加のクロスアカウント設定が必要です。Glue
Spark 構成で
spark.hadoop.hive.metastore.glue.catalogid <aws-account-id-for-glue-catalog>を設定します。 -
ターゲットの Glue Catalog が Databricks デプロイとは異なるリージョンにある場合は、
spark.hadoop.aws.region <aws-region-for-glue-catalog>も指定します。
-
spark.databricks.Hive metastore.glueCatalog.enabled true は、 AWS Glueへの接続に必要な設定です。
-
Spark には Hive の組み込みサポートが含まれていますが、これが使用されるかどうかは Databricks Runtime のバージョンによって異なります。
- 分離モード : Hive の組み込みサポートは無効です。Hive 1.2.1.spark2 のライブラリからロードされます
/databricks/glue/.Databricks Runtime 8.3 では、分離モードは有効になっており、無効にすることはできません。Databricks Runtime 7.3 LTS および Databricks Runtime 8.4 以降では、分離モードがデフォルトですが、無効にすることもできます。 - 組み込みモード : Hive の組み込みサポートが有効になっており、Hive のバージョンは Spark のバージョンによって異なります。 Databricks Runtime 7.3 LTS および Databricks Runtime 8.4 以降では、クラスターに
spark.databricks.hive.metastore.glueCatalog.isolation.enabled falseを設定することで組み込みモードを有効にできます。
- 分離モード : Hive の組み込みサポートは無効です。Hive 1.2.1.spark2 のライブラリからロードされます
-
資格情報のパススルーを有効にするには、
spark.databricks.passthrough.enabled true. これには、Databricks Runtime 7.3 LTS または Databricks Runtime 8.4 以降が必要です。 Databricks Runtime 7.3 LTS および Databricks Runtime 8.4 以降では、この設定により組み込みモードも自動的に有効になります。
制限
- AWSGlueで データカタログをメタストアとして使用すると、デフォルト よりも待機時間が長くなる可能性がありますDatabricks Hive metastore。詳細については、「トラブルシューティング」セクションの「Glue カタログでDatabricks Hive metastoreよりも待機時間が長くなる」を参照してください。
- デフォルトのデータベースは、
dbfs:(Databricks File System) スキームを使用して、場所を URI に設定して作成されます。 この場所には、AWS EMR や AWS Athena など、Databricks の外部にある AWS アプリケーションからアクセスすることはできません。 回避策として、LOCATION句を使用して、CREATE TABLEを呼び出すときにs3://mybucket/などのバケットの場所を指定します。または、デフォルトデータベース以外のデータベース内にテーブルを作成し、そのデータベースのLOCATIONを S3 の場所に設定します。 - GlueカタログとHive metastore 動的に切り替えることはできません。新しい Spark 構成を有効にするには、クラスターを再起動する必要があります。
- 資格情報のパススルーは、Databricks Runtime 8.4 以降でのみサポートされています。
- 次の機能はサポートされていません。
- Databricks Connect
- システム間の相互作用: 複数のシステム間で同じメタデータ・カタログまたは実際の表データを共有します。
スキーマの場所を指定するときは、URI の末尾にスラッシュを含める必要があります (s3://mybucketではなく s3://mybucket/ など)。スラッシュを省略すると、例外が発生する可能性があります。
トラブルシューティング
このセクションの内容:
- Glue カタログのレイテンシが Databricks Hive metastore よりも長い
- Databricks Runtime クラスターにアタッチされたインスタンスプロファイルはありません
- Glue Catalog のアクセス許可が不十分です
- ファイルに対してSQLを直接実行するときの
glue:GetDatabaseでの権限エラー - GlueカタログIDが一致しません
- Athena Catalog と Glue Catalog の競合
- 空のデータベースにテーブルを作成する
LOCATION - 共有 Glue カタログから Databricks ワークスペース間のテーブルにアクセスする
- 他のシステムで作成されたテーブルとビューへのアクセス
Glue カタログのレイテンシが Databricks Hive metastore よりも長い
Glueデータカタログを外部メタストアとして使用すると、ホストされている のデフォルトDatabricks Hive metastoreよりも待機時間が長くなる可能性があります。Databricks では、Glue Catalog クライアントでクライアント側のキャッシュを有効にすることをお勧めします。 次のセクションでは、テーブルとデータベースのクライアント側キャッシュを構成する方法について説明します。 クラスターと SQLウェアハウスのクライアント側キャッシュを構成できます。
- クライアント側のキャッシュは、
getTablesの listing table 操作では使用できません。 - 有効期限 (TTL) 構成は、キャッシュの有効性とメタデータの許容可能な古さとの間のトレードオフです。 特定のシナリオに適した TTL 値を選択します。
詳細については、AWS ドキュメントの「 Glue Catalog のクライアント側キャッシュの有効化 」を参照してください。
テーブル
spark.hadoop.aws.glue.cache.table.enable true
spark.hadoop.aws.glue.cache.table.size 1000
spark.hadoop.aws.glue.cache.table.ttl-mins 30
データベース
spark.hadoop.aws.glue.cache.db.enable true
spark.hadoop.aws.glue.cache.db.size 1000
spark.hadoop.aws.glue.cache.db.ttl-mins 30
Databricks Runtime クラスターにアタッチされたインスタンスプロファイルはありません
Databricks Runtime クラスターにインスタンスプロファイルがアタッチされていない場合、メタストア検索を必要とする操作を実行すると、次の例外が発生します。
org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: com.amazonaws.SdkClientException: Unable to load AWS credentials from any provider in the chain: [EnvironmentVariableCredentialsProvider: Unable to load AWS credentials from environment variables (AWS_ACCESS_KEY_ID (or AWS_ACCESS_KEY) and AWS_SECRET_KEY (or AWS_SECRET_ACCESS_KEY)), SystemPropertiesCredentialsProvider: Unable to load AWS credentials from Java system properties (aws.accessKeyId and aws.secretKey), com.amazonaws.auth.profile.ProfileCredentialsProvider@2245a35d: profile file cannot be null, com.amazonaws.auth.EC2ContainerCredentialsProviderWrapper@52be6b57: The requested metadata is not found at https://169.254.169.254/latest/meta-data/iam/security-credentials/];
目的のGlue Catalogにアクセスするための十分な権限を持つインスタンスプロファイルをアタッチします。
Glue Catalog のアクセス許可が不十分です
インスタンスプロファイルがメタストアオペレーションの実行に必要なアクセス許可を付与していない場合、次のような例外が発生します。
org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: MetaException(message:Unable to verify existence of default database: com.amazonaws.services.glue.model.AccessDeniedException: User: arn:aws:sts::<aws-account-id>:assumed-role/<role-id>/... is not authorized to perform: glue:GetDatabase on resource: arn:aws:glue:<aws-region-for-glue-catalog>:<aws-account-id-for-glue-catalog>:catalog (Service: AWSGlue; Status Code: 400; Error Code: AccessDeniedException; Request ID: <request-id>));
アタッチされたインスタンスプロファイルに十分な権限が指定されていることを確認します。 たとえば、前の例外では、インスタンスプロファイルに glue:GetDatabase を追加します。
ファイルに対してSQLを直接実行すると、 glue:GetDatabase で権限エラーが発生する
8.0 より前の Databricks Runtime バージョンでは、 ファイルに対して直接 SQL クエリを実行する場合、たとえば、次のようになります。
select * from parquet.`path-to-data`
次のようなエラーが発生する可能性があります。
Error in SQL statement: AnalysisException ... is not authorized to perform: glue:GetDatabase on resource: <glue-account>:database/parquet
これは、IAM ポリシーがリソース database/<datasource-format>(<datasource-format> は parquetや deltaなどのデータソース形式) に対してglue:GetDatabaseを実行するアクセス許可を付与していない場合に発生します。
IAM ポリシーにアクセス許可を追加して、database/<datasource-format>でのglue:GetDatabaseを許可します。
Spark SQL アナライザーの実装には制限があり、カタログに対するリレーションの解決を試みてから、ファイル上のSQLの登録済みデータソースに対する解決にフォールバックします。フォールバックが機能するのは、カタログに対する最初の解決の試みが例外なしで戻った場合のみです。
リソース database/<datasource-format> が存在しない場合でも、ファイルに対する SQL クエリへのフォールバックを正常に実行するには、Glue Catalog の IAM ポリシーで Glue Catalog に対する glue:GetDatabase アクションの実行を許可する必要があります。
Databricks Runtime 8.0 以降では、この問題は自動的に処理され、この回避策は不要になりました。
GlueカタログIDが一致しません
デフォルト では、Databricks クラスターは、Glue AWSデプロイに使用されたアカウントと同じ アカウントでDatabricks カタログに接続しようとします。
ターゲット カタログが デプロイとは異なる GlueAWSアカウントまたはリージョンにあり、 構成が設定されていない場合、クラスターはターゲットDatabricks カタログではなく、spark.hadoop.hive.metastore.glue.catalogidSparkGlue デプロイのAWS アカウントのDatabricks カタログに接続します。
spark.hadoop.hive.metastore.glue.catalogid構成が設定されていても、手順 2 の構成が正しく行われなかった場合、メタストアにアクセスすると、次のような例外が発生します。
org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: MetaException(message:Unable to verify existence of default database: com.amazonaws.services.glue.model.AccessDeniedException: User:
arn:aws:sts::<aws-account-id>:assumed-role/<role-id>/... is not authorized to perform: glue:GetDatabase on resource: arn:aws:glue:<aws-region-for-glue-catalog>:<aws-account-id-for-glue-catalog>:catalog (Service: AWSGlue; Status Code: 400; Error Code: AccessDeniedException; Request ID: <request-id>));
構成がこの記事の手順 2 と 6 と一致していることを確認します。
Athena Catalog と Glue Catalog の競合
2017 年 8 月 14 日より前に Amazon Athena または Amazon Redshift Spectrum を使用してテーブルを作成した場合、データベースとテーブルは、 AWS Glue データカタログとは別の Athena 管理カタログに保存されます。 これらのテーブルと Databricks Runtime を統合するには、 AWS Glue データカタログにアップグレードする必要があります。 そうしないと、Databricks Runtime が Glue カタログに接続できないか、一部のデータベースの作成とアクセスに失敗し、例外メッセージが不可解になる可能性があります。
たとえば、「デフォルト」データベースが Athena カタログには存在するが、Glue カタログには存在しない場合、次のようなメッセージで例外が発生します。
AWSCatalogMetastoreClient: Unable to verify existence of default database:
com.amazonaws.services.glue.model.AccessDeniedException: Please migrate your Catalog to enable access to this database (Service: AWSGlue; Status Code: 400; Error Code: AccessDeniedException; Request ID: <request-id>)
Amazon Athena ユーザーガイドの「AWS Glue データカタログへのアップグレード」の手順に従います。
空のデータベースにテーブルを作成する LOCATION
Glue Catalogのデータベースは、さまざまなソースから作成できます。 Databricks Runtimeによって作成されたデータベースには、デフォルトによる空でないLOCATIONフィールドがあります。Glue Consoleで直接作成されたデータベース、または他のソースからインポートされたデータベースには、空の LOCATION フィールドが含まれる場合があります。
Databricks Runtime が空の LOCATION フィールドを持つデータベースにテーブルを作成しようとすると、次のような例外が発生します。
IllegalArgumentException: Can not create a Path from an empty string
Glue Catalog でデータベースを作成し、 LOCATION フィールドに有効な空でないパスを指定するか、SQL でテーブルを作成するときに LOCATION を指定するか、データフレーム API で option("path", <some-valid-path>) を指定します。
AWS Glue コンソールでデータベースを作成するときは、名前のみが必要です。「説明」と「場所」はどちらもオプションとしてマークされています。 ただし、 Hive metastore 操作は「Location」に依存するため、 Databricks Runtimeで使用するデータベースに対して指定する必要があります。
共有 Glue カタログから Databricks ワークスペース間のテーブルにアクセスする
LOCATION キーワードは、データベース・レベル (すべてのテーブルのデフォルトのロケーションを制御する) で設定することも、CREATE TABLE 文の一部として設定することもできます。LOCATION で指定されたパスがマウントされたバケットである場合は、Glue Catalog を共有するすべての Databricks ワークスペースで同じマウント名を使用する必要があります。Glue Catalog は LOCATION 値で指定されたパスを使用してデータへの参照を保存するため、同じマウントポイント名を使用すると、各ワークスペースが S3 バケットに保存されているデータベースオブジェクトにアクセスできるようになります。
他のシステムで作成されたテーブルとビューへのアクセス
AWS Athena や Presto などの他のシステムによって作成されたテーブルやビューへのアクセスは、Databricks Runtime や Spark で機能する場合と機能しない場合があり、これらの操作はサポートされていません。 不可解なエラーメッセージで失敗する可能性があります。 たとえば、Athena、Databricks Runtime、または Spark によって作成されたビューにアクセスすると、次のような例外がスローされる場合があります。
IllegalArgumentException: Can not create a Path from an empty string
この例外は、Athena と Presto が Databricks Runtime と Spark で想定される形式とは異なる形式でビュー メタデータを格納するために発生します。