従来のプロビジョニングされたスループット モデルを展開する
このページで説明されているワークフローは非推奨です。代わりに、 「プロビジョニング スループット インフラストラクチャAPIsを参照してください。
MLflow transformersフレーバーを使用した記録済みモデル
モデル エンドポイントのプロビジョニングされたスループットを有効にするには、MLflow transformersフレーバーを使用してモデルをログに記録し、次のオプションから適切なモデル タイプ インターフェースを使用してtask引数を指定する必要があります。
"llm/v1/completions""llm/v1/chat""llm/v1/embeddings"
これらの引数は、モデルサービング エンドポイントに使用される API シグネチャを指定します。 これらのタスクと対応する入出力スキーマの詳細については 、MLflow のドキュメント を参照してください。
以下は、MLflow を使用して記録されたテキスト補完言語モデルをログに記録する方法の例です。
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3.3-70B-Instruct", torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.3-70B-Instruct")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
# Specify the llm/v1/xxx task that is compatible with the model being logged
task="llm/v1/completions",
# Specify an input example that conforms to the input schema for the task.
input_example={"prompt": np.array(["Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\nWhat is Apache Spark?\n\n### Response:\n"])},
# By passing the model name, MLflow automatically registers the Transformers model to Unity Catalog with the given catalog/schema/model_name.
registered_model_name=registered_model_name
# Optionally, you can set save_pretrained to False to avoid unnecessary copy of model weight and gain more efficiency.
save_pretrained=False
)
2.12 より前のMLflowを使用している場合は、代わりに同じmlflow.transformer.log_model()関数のmetadata問題内でタスクを指定する必要があります。
metadata = {"task": "llm/v1/completions"}metadata = {"task": "llm/v1/chat"}metadata = {"task": "llm/v1/embeddings"}
プロビジョニングされたスループットは、ベース GTE 埋め込みモデルと大規模 GTE 埋め込みモデルの両方をサポートします。以下は、プロビジョニングされたスループットで提供できるようにモデルAlibaba-NLP/gte-large-en-v1.5をログに記録する方法の例です。
model = AutoModel.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
tokenizer = AutoTokenizer.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
task="llm/v1/embeddings",
registered_model_name=registered_model_name,
# model_type is required for logging a fine-tuned BGE models.
metadata={
"model_type": "gte-large"
}
)
モデルが Unity Catalogにログインしたら、 UI を使用してプロビジョニング スループット エンドポイントを作成する に進み、プロビジョニング スループットを使用してモデルサービング エンドポイントを作成します。
プロビジョニングされたスループットにおける1秒あたりのトークン範囲
このセクションで説明するトピックは 、1 秒あたりのプロビジョニング推論容量に基づいてモデルを提供するプロビジョニング スループット ワークロード に適用されます。 以下のモデルが適用されます。
- Meta Llama 3.3
- Meta Llama 3.2 3B
- Meta Llama 3.2 1B
- Meta Llama 3.1
- GTE v1.5 (英語)
- BGE v1.5 (英語)
- DeepSeek R1 ( Unity Catalogでは利用できません)
- Meta Llama 3
- Meta Llama 2
- DBRX
- Mistral
- Mixtral
- MPT
プロビジョニングの推論能力にモデル 単位(1 秒あたりではない)を使用するサポートされているモデルについては 、プロビジョニング スループットのモデル単位を 参照してください。
このセクションでは、 Databricks基盤モデルAPIsのプロビジョニング スループット ワークロードの 1 秒あたりのノートを測定する方法とその理由について説明します。
大規模言語モデル (LLM) のパフォーマンスは、多くの場合、1 秒あたりのトークン数で測定されます。本番運用モデルサービング エンドポイントを構成するときは、アプリケーションがエンドポイントに送信するリクエストの数を考慮することが重要です。 こうすることで、レイテンシに影響を与えないようにエンドポイントをスケーリングするように構成する必要があるかどうかを把握できます。
プロビジョニングされたスループットで展開されたエンドポイントのスケールアウト範囲を構成する場合、Databricks はトークンを使用してシステムに入力される内容について推論する方が簡単であることに気付きました。
トークンとは何ですか?
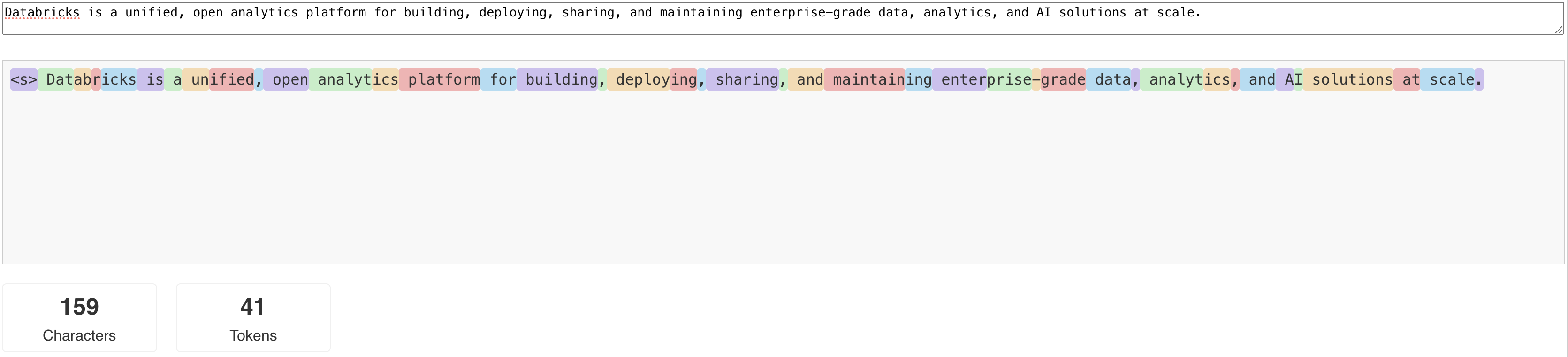
LLM は、 トークン と呼ばれる単位でテキストを読み取り、生成します。「いつか」は単語またはサブワードにすることができ、テキストを「乃至」に分割するための正確なルールはモデルごとに異なります。 たとえば、オンライン ツールを使用して、Llama のトークナイザーが単語をトークンに変換する方法を確認できます。
次の図は、Llama トークナイザーがテキストを分割する方法の例を示しています。
LLM のパフォーマンスを 1 秒あたりのトークン数で測定するのはなぜですか?
従来、サービングエンドポイントは、1 秒あたりの並列要求数 (RPS) に基づいて設定されていました。 ただし、LLM 推論要求にかかる時間は、渡されるトークンの数と生成されるトークンの数によって異なり、要求間で不均衡になる可能性があります。 したがって、エンドポイントに必要なスケールアウトの量を決定するには、リクエストの内容 (トークン) の観点からエンドポイントのスケールを測定する必要があります。
ユースケースによって、入力トークンと出力トークンの比率が異なります。
- 入力コンテキストの長さのばらつき : 短い質問など、少数の入力トークンのみを含むリクエストもあれば、要約用の長いドキュメントのように、数百または数千のトークンが含まれるリクエストもあります。 この変動性により、RPS のみに基づくサービング エンドポイントの設定は、さまざまな要求のさまざまな処理要求に対応しないため、困難になります。
- ユースケースに応じて出力の長さが変化する : LLM のユースケースが異なると、出力トークンの長さが大きく異なる可能性があります。出力トークンの生成は LLM 推論の中で最も時間のかかる部分であるため、スループットに大きな影響を与える可能性があります。たとえば、要約では、より短く簡潔な応答が求められますが、記事や製品の説明の作成などのテキスト生成では、はるかに長い回答が生成されることがあります。
エンドポイントの 1 秒あたりのトークンの範囲を選択するにはどうすればよいですか?
プロビジョニングされたスループットを提供するエンドポイントは、エンドポイントに送信できる 1 秒あたりのトークンの範囲に基づいて構成されます。エンドポイントは、本番運用アプリケーションの負荷を処理するためにスケールアップおよびスケールダウンします。 エンドポイントがスケーリングされる 1 秒あたりのトークンの範囲に基づいて、時間ごとに課金されます。
プロビジョニングされたスループット サービング エンドポイントの 1 秒あたりのトークン範囲がユースケースに適しているかを知る最良の方法は、代表的なデータセットを使用して負荷テストを実行することです。「独自の LLM エンドポイント ベンチマークを実施する」を参照してください。
考慮すべき重要な要素が 2 つあります。
- Databricks が LLM の 1 秒あたりのトークンのパフォーマンスを測定する方法。
- オートスケールの仕組み。
DatabricksがLLMの1秒あたりのトークンパフォーマンスを測定する方法
Databricks は、RAGのユースケースに共通する要約タスクを表すワークロードに対してエンドポイントをベンチマークします。 具体的には、ワークロードは次のもので構成されます。
- 2048個の入力トークン
- 256個の出力トークン
表示されるトークン範囲は、入力トークンと出力トークンのスループットを 組み合わせ 、デフォルトでは、スループットとレイテンシのバランスを取るために最適化されます。
Databricks のベンチマークでは、ユーザーはリクエストごとに 1 つのバッチ サイズで、1 秒あたりにその数のトークンを同時にエンドポイントに送信できます。これは、エンドポイントに同時に到達する複数のリクエストをシミュレートし、本番運用でエンドポイントを実際に使用する方法をより正確に表します。
- たとえば、プロビジョニングされたスループット サービング エンドポイントの設定レートが 1 秒あたり 2304 トークン (2048 + 256) の場合、入力が 2048 トークンで出力が 256 トークンと予想される単一のリクエストの実行には約 1 秒かかると予想されます。
- 同様に、レートが 5600 に設定されている場合、上記の入力トークン数と出力トークン数を持つ単一のリクエストの実行には約 0.5 秒かかると予想されます。つまり、エンドポイントは約 1 秒で 2 つの同様のリクエストを処理できます。
ワークロードが上記と異なる場合、記載されているプロビジョニングされたスループット レートに応じてレイテンシが変化することが予想されます。前述のように、出力トークンを多く生成すると、入力トークンを多く含めるよりも時間がかかります。バッチ推論を実行していて、完了までにかかる時間を見積もる場合は、入力トークンと出力トークンの平均数を計算し、上記の Databricks ベンチマーク ワークロードと比較できます。
- たとえば、1000 行があり、平均入力トークン数が 3000、平均出力トークン数が 500、プロビジョニング スループットが 1 秒あたり 3500トークンの場合、平均トークン数が Databricksベンチマーク よりも 大きい ため、合計 1000 秒 (1 行あたり 1 秒) より長く かかる可能性があります。
- 同様に、1000 行、平均入力が 1500 トークン、平均出力が 100 トークン、プロビジョニング スループットが 1600 トークン/秒の場合、平均トークン数がDatabricks ベンチマークよりも 少ない ため、合計 1000 秒 (1 行あたり 1 秒) 未満で完了 する可能性があります。
オートスケールの仕組み
モデルサービングは、アプリケーションの 1 秒あたりのネットワーク需要を満たすために、基礎となるコンピュートをスケーリングする高速オートスケール システムを備えています。 Databricks は、プロビジョニングされたスループットを 1 秒あたりのトークンのチャンク単位でスケールアップするため、プロビジョニングされたスループットの追加単位は、使用している場合にのみ課金されます。
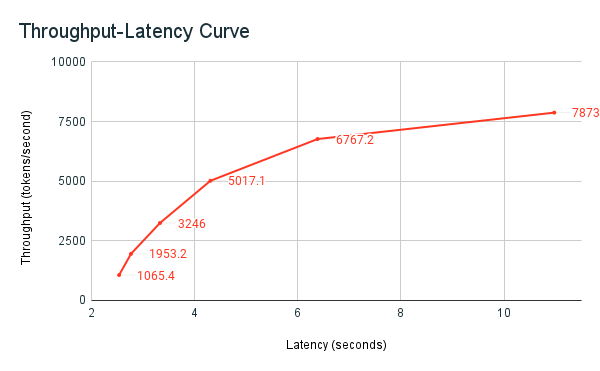
次のスループット レイテンシ グラフは、並列リクエストの数が増加した、テスト済みのプロビジョニング済みスループット エンドポイントを示しています。最初のポイントは 1 つのリクエストを表し、2 番目は 2 つの並列リクエスト、3 番目は 4 つの並列リクエストを表します。リクエスト数が増加し、1 秒あたりのトークンの需要が増加すると、プロビジョニングされたスループットも増加することがわかります。この増加は、オートスケールが利用可能なコンピュートを増加させることを示します。 ただし、並列リクエストが増えるにつれて、スループットが停滞し始め、1 秒あたり約 8000 トークンの制限に達することが分かる場合があります。割り当てられたコンピュート が同時に使用されるため、処理される前にキューで待機する必要があるリクエストが増えるため、合計レイテンシが増加します。
スケール トゥ ゼロをオフにし、サービス エンドポイントで最小スループットを構成することで、スループットの一貫性を維持できます。こうすることで、エンドポイントがスケールアップするまで待つ必要がなくなります。
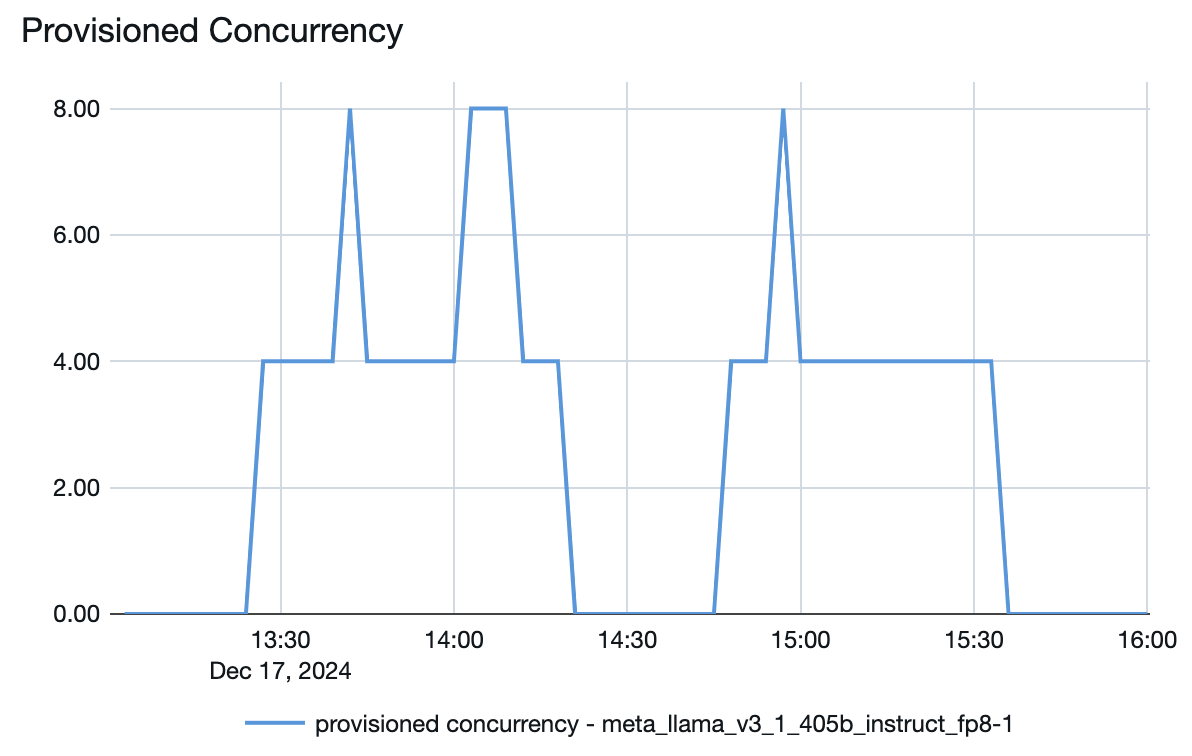
モデルサービング エンドポイントから、需要に応じてリソースがどのようにスピンアップまたはスピンダウンされるかを確認することもできます。
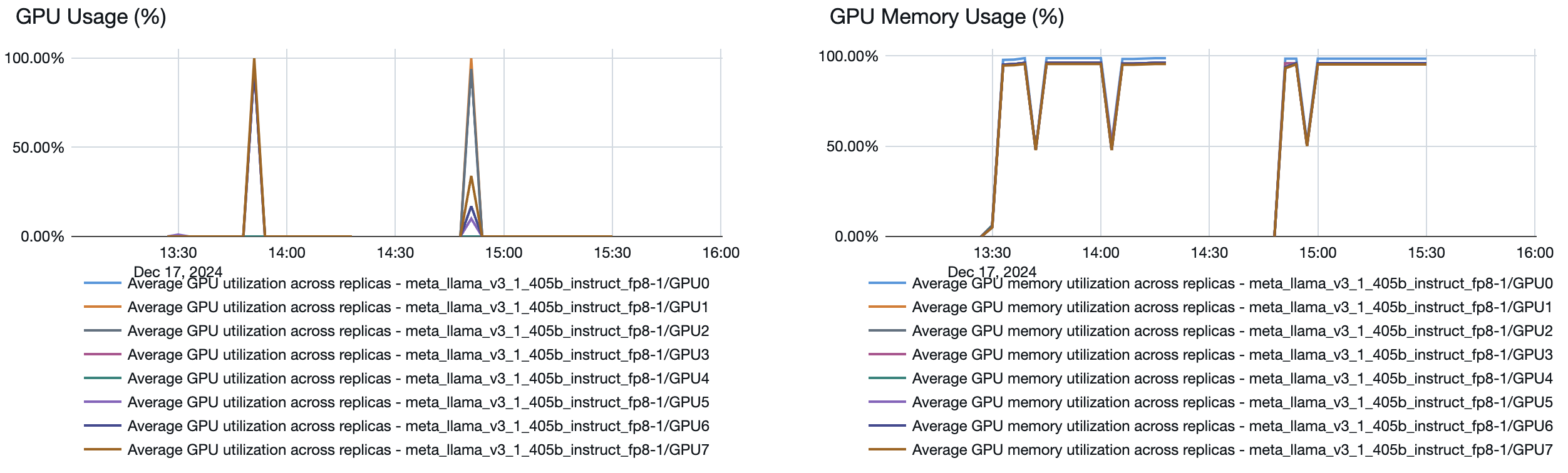
トラブルシューティング
プロビジョニングされたスループット サービング エンドポイントが、指定されたよりも 1 秒あたりのトークン数が少ないレートで実行される場合は、次の点を確認して、エンドポイントが実際にどの程度スケーリングされたかを確認します。
- エンドポイントメトリクスにおけるプロビジョン済み同時実行数のプロット。
- プロビジョニングされたスループット エンドポイントの最小帯域サイズ。
- エンドポイントの Served entity details に移動し、Up toドロップダウンで 1 秒あたりの最小トークン数の値を確認します。
次の式を使用して、エンドポイントが実際にどの程度拡大されたかを計算できます。
- プロビジョニングされた同時実行数 * 最小バンドサイズ / 4
たとえば、上記の Llama 3.1 405B モデルのプロビジョニングされた同時実行プロットでは、プロビジョニングされた同時実行の最大数は 8 です。エンドポイントを設定する場合、最小バンド サイズは 1 秒あたり 850 トークンでした。この例では、エンドポイントは最大で次のようにスケーリングされます。
- 8 (プロビジョニングの同時実行数) * 850 (最小バンド サイズ) / 4 = 1 秒あたり 1700 ミント