独自のLLMエンドポイントベンチマークを実施
このページで説明するトピックは、トークン /秒 に基づいてプロビジョニング推論容量を提供するプロビジョニング スループット ワークロードに適用されます。 次のモデルが適用されます。
- Meta Llama 3.3
- Meta Llama 3.2 3B
- Meta Llama 3.2 1B
- Meta Llama 3.1
- GTE v1.5 (英語)
- BGE v1.5 (英語)
- DeepSeek R1 (Unity Catalog では使用できません)
- Meta Llama 3
- Meta Llama 2
- DBRX
- Mistral
- Mixtral
- MPT
プロビジョニングの推論能力にモデル 単位(1 秒あたりではない)を使用するサポートされているモデルについては 、プロビジョニング スループットのモデル単位を 参照してください。
この記事では、LLM エンドポイントのベンチマークに関する Databricks の推奨ノートブックの例を示します。 また、Databricks が LLM 推論を実行し、レイテンシとスループットをエンドポイントのパフォーマンスメトリクスとして計算する方法についても簡単に紹介します。
DatabricksでのLLM推論は、基盤モデルAPIsのプロビジョニング スループット モードの 1 秒あたりの時間を測定します。 「従来のプロビジョニングされたスループット モデルのデプロイ」を参照してください。
ベンチマーク例ノートブック
次のノートブックを Databricks 環境にインポートし、LLM エンドポイントの名前を指定してロード テストを実行できます。
LLM エンドポイントのベンチマーク
LLM推論の紹介
LLM は、次の 2 段階のプロセスで推論を実行します。
- 事前入力 : 入力プロンプトのトークンが並列で処理されます。
- デコード では、テキストは一度に 1 つのトークンを自動回帰的に生成されます。 生成された各トークンは入力に追加され、モデルにフィードバックされて次のトークンが生成されます。 LLM が特別な停止トークンを出力したとき、またはユーザー定義の条件が満たされたときに、生成は停止します。
ほとんどの本番運用アプリケーションにはレイテンシーの予算があり、 Databricks では、そのレイテンシーの予算を考慮してスループットを最大化することを推奨しています。
- 入力トークンの数は、要求を処理するために必要なメモリに大きな影響を与えます。
- 出力トークンの数は、全体的な応答レイテンシを支配します。
Databricks は LLM 推論を次のサブメトリクスに分割します。
- 最初のトークンまでの時間 (TTFT):これは、ユーザーがクエリを入力してからモデルの出力を表示し始めるまでの時間です。応答の待ち時間が短いことは、リアルタイムのやり取りでは不可欠ですが、オフラインのワークロードではそれほど重要ではありません。このメトリクスは、プロンプトを処理してから最初の出力トークンを生成するのに必要な時間によって駆動されます。
- 出力トークンあたりの時間 (TPOT): システムにクエリを実行する各ユーザーの出力トークンを生成する時間。 このメトリクスは、各ユーザーがモデルの「速度」をどのように認識するかに対応しています。 たとえば、トークンあたり 100 ミリ秒の TPOT は、1 秒あたり 10 トークン、つまり 1 分あたり ~450 ワードであり、これは一般的な人が読むよりも高速です。
これらのメトリクスに基づいて、合計レイテンシとスループットは次のように定義できます。
- レイテンシ = TTFT + (TPOT) * (生成されるトークンの数)
- スループット = すべての同時実行要求に対する 1 秒あたりの出力トークンの数
Databricksでは、LLM サービスエンドポイントは、複数の並列リクエストを持つクライアントから送信される負荷に合わせてスケーリングできます。レイテンシとスループットの間にはトレードオフがあります。 これは、 LLM のサービス エンドポイントでは、並列要求が同時に処理される可能性があるためです。 並列要求の負荷が低い場合、レイテンシは可能な限り低くなります。 ただし、要求の負荷を増やすと、待機時間が長くなる可能性がありますが、スループットも増加する可能性があります。 これは、1秒あたり2つのリクエストに相当するトークンを2倍以下の時間で処理できるためです。
したがって、システムへの並列リクエストの数を制御することは、レイテンシーとスループットのバランスを取るための中核となります。 低レイテンシーのユースケースがある場合は、レイテンシーを低く抑えるために、エンドポイントに送信する並列リクエストを減らしたいと考えています。 高スループットのユースケースがある場合は、レイテンシーを犠牲にしてもスループットを高くする価値があるため、エンドポイントを多数の同時実行リクエストで飽和状態にする必要があります。
- 高スループットのユースケースには、バッチ推論やその他のユーザー向け以外のタスクが含まれる場合があります。
- 低レイテンシのユースケースには、即時の応答を必要とするリアルタイムアプリケーションが含まれる場合があります。
Databricks ベンチマーキングハーネス
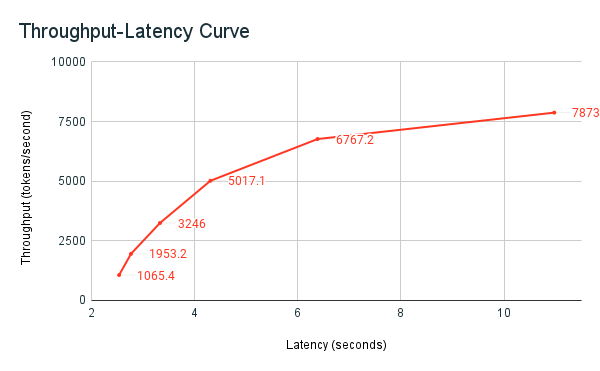
以前に共有された ベンチマーク サンプル ノートブック は、Databricks ベンチマーク ハーネスです。 ノートブックには、 すべての リクエストの合計レイテンシとスループットメトリクスが表示され、異なる数の並列リクエストのスループットとレイテンシ曲線がプロットされます。 Databricks エンドポイントオートスケール戦略は、レイテンシーとスループットのバランスを取ります。 ノートブックでは、エンドポイントに対してクエリを実行する並列ユーザーが増えると、待機時間とスループットが増加することがわかります。
ただし、並列リクエストの数が増えると、スループットが横ばいになり始め、毎秒約 8000 トークンの制限に達することもわかってきます。 このプラトーは、エンドポイントにプロビジョニングされたスループットによって、実行できるワーカーと並列リクエストの数が制限されるために発生します。 エンドポイントが同時に処理できる範囲を超えるリクエストが行われると、追加のリクエストがキューで待機するため、合計レイテンシーは増加し続けます。
LLM パフォーマンス ベンチマークに関する Databricks の哲学の詳細については、「LLM 推論パフォーマンス エンジニアリング: ベスト プラクティス」ブログで説明されています。