Spotfire Analystへの接続
このドキュメントは廃止されており、更新されない可能性があります。このコンテンツに記載されている製品、サービス、またはテクノロジはサポートされなくなりました。Spotfire のカスタム コネクタを参照してください。
この記事では、Spotfire アナリストを Databricks クラスター または Databricks SQL ウェアハウスと共に使用する方法について説明します。
要件
-
Databricksワークスペース内のクラスターまたはSQL ウェアハウス。
-
クラスターまたはウェアハウス SQL接続の詳細、特に Server Hostname 、 Port 、および HTTP Path の値。
-
Databricksの個人的なアクセス権。 個人的なアクセストークンを作成するには、 「ワークスペース ユーザー向けの個人的なアクセストークンを作成する」のステップに従います。
自動化されたツール、システム、スクリプト、アプリで認証する際のセキュリティのベストプラクティスとして、DatabricksではOAuth トークンを使用することをお勧めします。
パーソナルアクセストークン認証 を使用する場合、 Databricks では、ワークスペース ユーザーではなく、サービスプリンシパル に属する パーソナルアクセストークン を使用することをお勧めします。 サービスプリンシパルのトークンを作成するには、「 サービスプリンシパルのトークンの管理」を参照してください。
繋ぐステップ
- Spotfire アナリストのナビゲーション バーで、プラス ( ファイルとデータ ) アイコンをクリックし、 [接続] を クリックします。
- Databricks を選択し、 [新しい接続] をクリックします。
- Apache Spark SQL ダイアログの [全般 ] タブの [ サーバー] に、ステップ 1 の [サーバーホスト名] と [ポート] フィールドの値をコロンで区切って入力します。
- 認証方法 では、 ユーザー名とパスワード を選択します。
- ユーザー名 には「
token」と入力します。 - [Password] に、ステップ 1 の個人的なアクセス許可を入力します。
- [詳細設定] タブの [Thrift トランスポート モード] で [HTTP] を選択します。
- HTTP Path には、ステップ 1 の HTTP Path フィールドの値を入力します。
- [全般] タブで、 [接続] をクリックします。
- 接続が成功したら、 [データベース] リストで使用するデータベースを選択し、 [OK] をクリックします。
分析するDatabricksデータを選択する
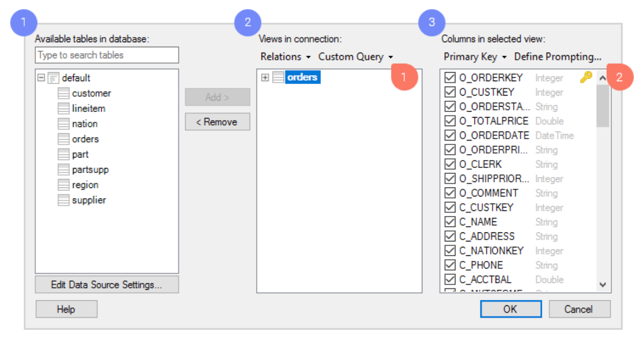
「接続のビュー」 ダイアログでデータを選択します。
-
Databricks で利用可能なテーブルを参照します。
-
必要なテーブルをビューとして追加します。これが Spotfire で分析するデータ テーブルになります。
-
各ビューごとに、含める列を決定できます。非常に具体的かつ柔軟なデータ選択を作成したい場合は、このダイアログで次のようなさまざまな強力なツールにアクセスできます。
- カスタムクエリ。カスタム クエリを使用すると、カスタム SQL クエリを入力して、分析するデータを選択できます。
- 促す。データの選択は分析ファイルのユーザーに任せてください。選択した列に基づいてプロンプトを構成します。次に、分析を開いたエンドユーザーは、関連する値のデータのみを制限して表示することを選択できます。たとえば、ユーザーは特定の期間内または特定の地理的地域のデータを選択できます。
-
OK をクリックします。
Databricksへのクエリのプッシュダウンまたはデータのインポート
分析するデータを選択したら、最後のステップとして、Databricks からデータを取得する方法を選択します。分析に追加するデータ テーブルの概要が表示され、各テーブルをクリックしてデータの読み込み方法を変更できます。
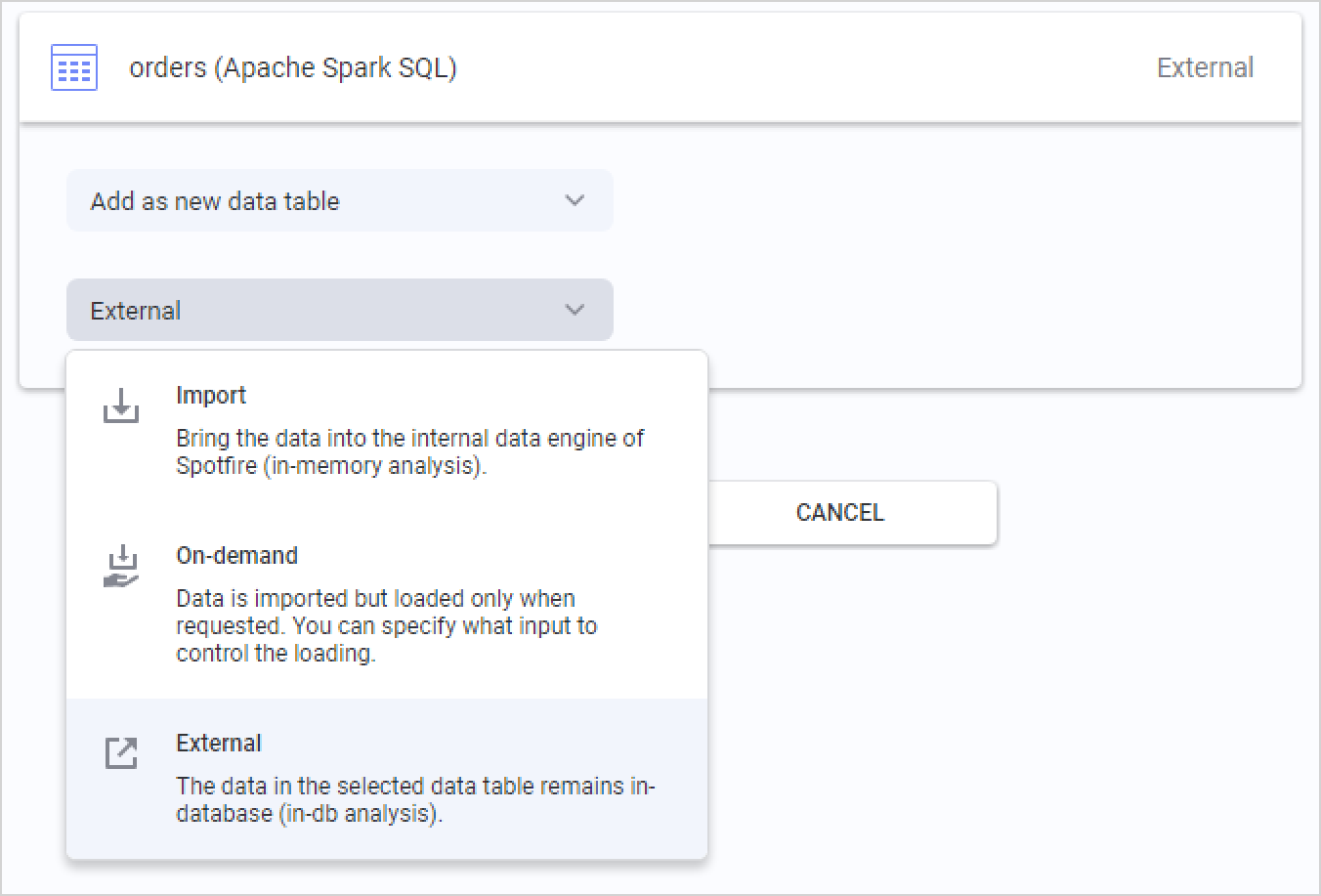
Databricks のデフォルト オプションは、 External です。つまり、データ テーブルは Databricks のデータベース内に保持され、Spotfire は分析でのアクションに基づいて、関連するデータ スライスに対してさまざまなクエリをデータベースにプッシュします。
また、 「インポート済み」 を選択すると、Spotfire によってデータ テーブル全体が事前に抽出され、ローカルのメモリ内分析が可能になります。データ テーブルをインポートする場合は、TIBCO Spotfire の組み込みのメモリ内データ エンジンの分析関数も使用します。
3 番目のオプションは オンデマンド (動的WHERE句に対応) です。これは、分析におけるユーザー アクションに基づいてデータのスライスが抽出されることを意味します。データのマーク付けやフィルタリング、ドキュメントのプロパティの変更などのアクションとなる基準を定義できます。オンデマンドのデータ読み込みは、 外部 データ テーブルと組み合わせることもできます。