Lookerに接続する
この記事では、Looker DatabricksクラスターまたはDatabricks SQL ウェアハウス (旧称Databricks SQL エンドポイント) で を使用する方法について説明します。
永続派生テーブル(PDT)が有効になっている場合、デフォルトでは、Lookerは関連付けられたデータベースに接続して5分ごとにPDTを再生成します。 Databricks では、コンピュートのコストを過剰に発生させないように、デフォルトの頻度を変更することをお勧めします。 詳細については、「 永続派生テーブル (PDT) の有効化と管理」を参照してください。
必要条件
Lookerに手動で接続する前に、以下のものが必要です。
-
ワークスペース内のクラスターまたはSQL ウェアハウス。Databricks
-
クラスターまたはウェアハウス SQL接続の詳細、特に [Server Hostname ]、[ Port ]、 および [HTTP Path ] の値。
-
Databricksの個人的なアクセス権。 個人的なアクセストークンを作成するには、 「ワークスペース ユーザー向けの個人的なアクセストークンを作成する」のステップに従います。
自動化されたツール、システム、スクリプト、アプリで認証する際のセキュリティのベストプラクティスとして、Databricks では OAuth トークンを使用することをお勧めします。
パーソナルアクセストークン認証 を使用する場合、 Databricks では、ワークスペース ユーザーではなく 、サービスプリンシパル に属する パーソナルアクセストークン を使用することをお勧めします。 サービスプリンシパルのトークンを作成するには、「 サービスプリンシパルのトークンの管理」を参照してください。
Lookerに手動で接続する
Lookerに手動で接続するには、次の操作を行います。
-
Lookerで、[Admin] > [Connections]>[Add Connection ]をクリックします。
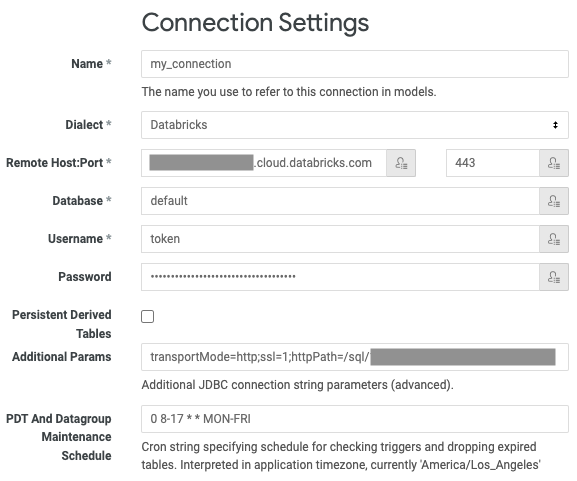
-
接続に固有の名前を入力してください 。
接続名には、小文字、数字、アンダースコアのみを含める必要があります。 他の文字は受け入れられる場合がありますが、後で予期しない結果が生じる可能性があります。
-
[Dialect ] で [ Databricks ] を選択します。
-
[Remote Host ] には、要件の [Server Hostname ] を入力します。
-
[ポート ] に、要件の ポート を入力します。
-
[データベース ] に、接続を介してアクセスするワークスペース内のデータベースの名前を入力します (例:
default)。 -
[Username] に「
token」と入力します。 -
[パスワード] には、要件の個人用アクセス トークンを入力します。
-
[Additional Params ] に「
transportMode=http;ssl=1;httpPath=<http-path>」と入力し、<http-path>を要件の HTTP パス 値に置き換えます。ワークスペースで Unity Catalog が有効になっている場合は、デフォルト カタログを追加で設定します。 「
ConnCatalog=<catalog-name>」と入力し、<catalog-name>をカタログの名前に置き換えます。 -
[ PDT And Datagroup Maintenance Schedule] に有効な
cron式を入力して、PDT の再生成のデフォルトの頻度を変更します。 デフォルトの頻度は 5 分ごとです。 -
クエリを他のタイム ゾーンに変換する場合は、 クエリ タイム ゾーン を調整します。
-
残りのフィールドについては、特に次のデフォルトをそのまま使用します。
- [最大接続数 ] と [接続プール タイムアウト] はデフォルトのままにします。
- データベースのタイムゾーンは空白のままにしておきます (すべてをUTCで保存していると仮定します)。
-
[Test These Settings ] をクリックします。
-
テストが成功したら、「 接続を追加 」をクリックしてください。
Lookerでデータベースをモデル化する
このセクションでは、プロジェクトを作成し、ジェネレータを実行します。 次の手順では、接続用のデータベースに永続テーブルが格納されていることを前提としています。
-
[開発] メニューで、[ 開発] Mode をオンにします。
-
「 開発」をクリックして>LookMLプロジェクトを管理 します。
-
「 新しいLookMLプロジェクト 」をクリックします。
-
一意の プロジェクト名 を入力します。
プロジェクト名には、小文字、数字、アンダースコアのみを含める必要があります。 他の文字は受け入れられる場合がありますが、後で予期しない結果が生じる可能性があります。
-
[接続] で、ステップ 2 の接続の名前を選択します。
-
[スキーマ] に「
default」と入力します。ただし、接続を介してモデル化する他のデータベースがある場合を除く。 -
残りのフィールドについては、特に次のデフォルトをそのまま使用します。
- 「 開始点 」を「データベース・スキーマからモデルを生成 」に設定したままにします。
- 「ビューの構築元 」は「 すべてのテーブル 」に設定したままにします。
-
[プロジェクトの作成 ] をクリックします。
プロジェクトを作成してジェネレータを実行すると、Lookerは1つの .model ファイルと複数の .view ファイルを含むユーザーインターフェースを表示します。 .modelファイルには、スキーマ内のテーブルと、それらの間で検出された結合関係が表示され、.viewファイルには、スキーマ内の各テーブルで使用可能な各ディメンション(列)が一覧表示されます。
次のステップ
プロジェクトの作業を開始するには、Lookerウェブサイトの次のリソースを参照してください。
永続派生テーブル (PDT) の有効化と管理
Lookerは、 永続派生テーブル (PDT)を作成することで、クエリ時間とデータベース負荷を軽減できます。 PDTは、Lookerがデータベース内のスクラッチスキーマに書き込む派生テーブルです。 その後、Lookerは指定したスケジュールでPDTを再生成します。 詳細については、Looker のドキュメントの 「永続派生テーブル (PDT)」 を参照してください。
データベース接続の PDT を有効にするには、その接続で [永続派生テーブル ] を選択し、画面上の指示を完了します。 詳細については、Lookerドキュメントの 「永続派生テーブル 」および 「PDTプロセスの個別のログイン資格情報の設定 」を参照してください。
PDTが有効になっている場合、デフォルトでは、Lookerは関連付けられたデータベースに接続して5分ごとにPDTを再生成します。 Looker は、関連付けられている Databricks リソースが停止している場合は再起動します。 Databricks では、データベース接続の PDT And Datagroup Maintenance Schedule フィールドを有効な cron式に設定して、デフォルトの頻度を変更することをお勧めします。 詳細については、ドキュメントの PDT とデータグループのメンテナンス スケジュール Lookerを参照してください。
PDT を有効にするか、既存のデータベース接続の PDT 再生成頻度を変更するには、[ 管理] > [データベース接続 ] をクリックし、データベース接続の横にある [編集 ] をクリックして、前の指示に従います。