Tracing LiteLLM🚄
LiteLLM is an open-source LLM Gateway that allow accessing 100+ LLMs in the unified interface.
MLflow Tracing provides automatic tracing capability for LiteLLM. By enabling auto tracing
for LiteLLM by calling the mlflow.litellm.autolog function, MLflow will capture traces for LLM invocation and log them to the active MLflow Experiment.
import mlflow
mlflow.litellm.autolog()
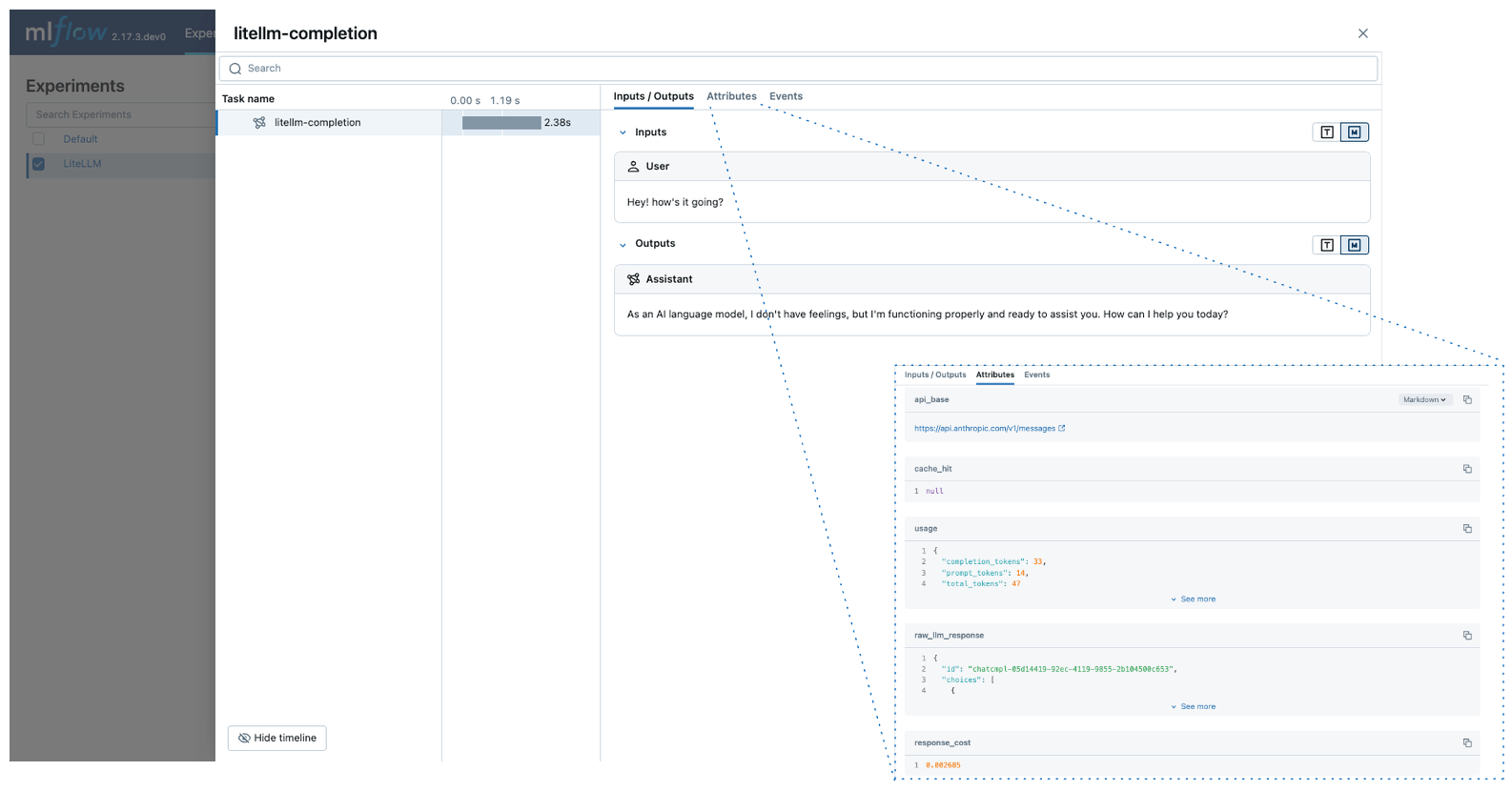
MLflow trace automatically captures the following information about LiteLLM calls:
- Prompts and completion responses
- Latencies
- Metadata about the LLM provider, such as model name and endpoint URL
- Token usages and cost
- Cache hit
- Any exception if raised
On serverless compute clusters, autologging is not automatically enabled. You must explicitly call mlflow.litellm.autolog() to enable automatic tracing for this integration.
Prerequisites
Before running the examples below, make sure you have:
-
Databricks credentials configured: If running outside of Databricks, set your environment variables:
Bashexport DATABRICKS_HOST="https://your-workspace.cloud.databricks.com"
export DATABRICKS_TOKEN="your-personal-access-token"tipIf you're running inside a Databricks notebook, these are automatically set for you.
-
LLM provider API keys: Ensure your API keys are configured. For production environments, use AI Gateway or Databricks secrets instead of hardcoded values for secure API key management.
Bashexport ANTHROPIC_API_KEY="your-anthropic-api-key" # For Anthropic models
export OPENAI_API_KEY="your-openai-api-key" # For OpenAI models
# Add other provider keys as needed
Basic Example
import mlflow
import litellm
# Enable auto-tracing for LiteLLM
mlflow.litellm.autolog()
# Set up MLflow tracking on Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/litellm-demo")
# Call Anthropic API using LiteLLM
response = litellm.completion(
model="claude-3-5-sonnet-20241022",
messages=[{"role": "user", "content": "Hey! how's it going?"}],
)
Async API
MLflow supports tracing LiteLLM's async APIs:
mlflow.litellm.autolog()
response = await litellm.acompletion(
model="claude-3-5-sonnet-20241022",
messages=[{"role": "user", "content": "Hey! how's it going?"}],
)
Streaming
MLflow supports tracing LiteLLM's sync and async streaming APIs:
mlflow.litellm.autolog()
response = litellm.completion(
model="claude-3-5-sonnet-20241022",
messages=[{"role": "user", "content": "Hey! how's it going?"}],
stream=True,
)
for chunk in response:
print(chunk.choices[0].delta.content, end="|")
MLflow will record concatenated outputs from the stream chunks as a span output.
For production environments, use AI Gateway or Databricks secrets instead of hardcoded values for secure API key management.
Disable auto-tracing
Auto tracing for LiteLLM can be disabled globally by calling mlflow.litellm.autolog(disable=True) or mlflow.autolog(disable=True).
Additional resources
- Understand tracing concepts - Learn how MLflow captures and organizes trace data
- Debug and observe your app - Use the Trace UI to analyze your LiteLLM application's behavior
- Evaluate your app's quality - Set up quality assessment for your multi-provider LLM application