IAM 認証情報を使用した S3 へのアクセス SCIM によるパススルー (レガシー)
このドキュメントは廃止されており、更新されない可能性があります。
資格情報のパススルーは、Databricks Runtime 15.0 以降で非推奨となり、将来の Databricks Runtime バージョンで削除される予定です。 Databricks では、Unity Catalog にアップグレードすることをお勧めします。 Unity Catalog は、アカウント内の複数のワークスペースにわたるデータアクセスを一元的に管理および監査するための場所を提供することで、データのセキュリティとガバナンスを簡素化します。 「Unity Catalog とは」を参照してください。
IAMS3Databricks資格情報パススルーを使用すると、 へのログインに使用する ID を使用して クラスターからDatabricks バケットに対して自動的に認証できます。クラスター IAM 資格情報パススルーを有効にすると、そのクラスターで実行するコマンドは、ID を使用して S3 でデータの読み取りと書き込みを行うことができます。 IAM 認証情報のパススルーには、 インスタンスプロファイルを使用して S3 バケットへのアクセスを保護する場合に比べて、主に 2 つの利点があります。
- IAM 資格情報パススルーを使用すると、データ アクセス ポリシーが異なる複数のユーザーが 1 つの Databricks クラスターを共有して、データ セキュリティを常に維持しながら S3 内のデータにアクセスできます。 インスタンスプロファイルは、1 つの IAMロールにのみ関連付けることができます。 これには、 Databricks クラスターのすべてのユーザーが、そのロールとそのロールのデータ アクセス ポリシーを共有する必要があります。
- IAM 認証情報のパススルーは、ユーザーを ID に関連付けます。 これにより、CloudTrail を介した S3 オブジェクトのログ記録が可能になります。 すべての S3 アクセスは、CloudTrail ログの ARN を介してユーザーに直接関連付けられます。
必要条件
- プレミアムプラン以上。
- AWS 管理者のアクセス:
- IAMロールとポリシー デプロイのAWS アカウントにあります。Databricks
- S3 バケットの AWS アカウント。
- Databricks 管理者アクセスを使用してインスタンスプロファイルを設定します。
メタインスタンスプロファイルの設定
IAM 資格情報パススルーを使用するには、まず、ユーザーに割り当てる IAMロールを引き受けるために、少なくとも 1 つの メタ インスタンスプロファイル を設定する必要があります。
IAMロール は、AWSで ID が実行できる操作と実行できない操作を決定するポリシー を持つ AWS ID です。 インスタンスプロファイル は、ロールIAMのコンテナであり、次の場合にロール情報をEC2インスタンスに渡すために使用できます インスタンスが起動します。インスタンスプロファイル を使用すると、Databricks クラスターからデータにアクセスできます AWSキーをノートブックに埋め込む必要はありません。
インスタンスプロファイルを使用すると、クラスターでのロールの設定が非常に簡単になりますが、インスタンスプロファイルは 1つの IAMロールにのみ関連付けることができます。これには、 Databricks クラスターのすべてのユーザーが、そのロールとそのロールのデータ アクセス ポリシーを共有する必要があります。ただし、 IAMロールを使用して、他の IAMロールを引き受けたり、データに直接アクセスしたりできます 自分自身。 1 つのロールの資格情報を使用して別のロールを引き受けることは、ロールと呼ばれます チェーン。
IAM 資格情報のパススルーにより、管理者はインスタンスプロファイルが使用している IAMロールを分割できます。 ユーザーがデータにアクセスするために使用するロール。 Databricksでは、インスタンスロールを メタIAMロール と呼び、データアクセスロールを データIAMロール と呼びます。インスタンスプロファイルと同様に、 meta インスタンスプロファイル は、meta IAMロールのコンテナです。
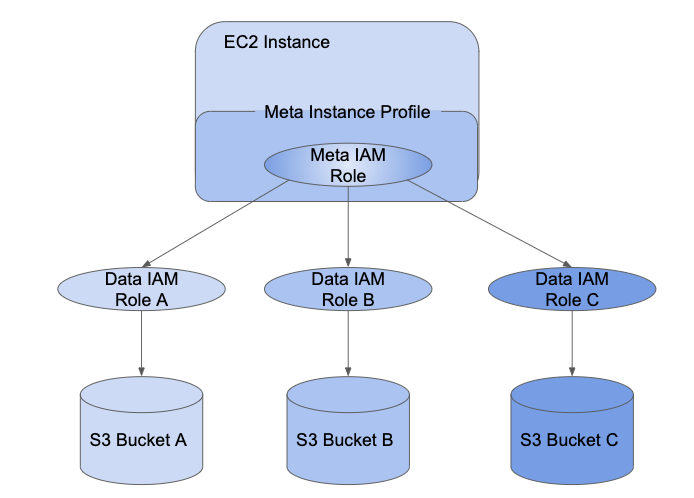
ユーザーには、 を使用してデータIAM ロールへのアクセス権が付与されます。SCIMAPIID プロバイダーにロールをマッピングしている場合、それらのロールは Databricks SCIM API に同期されます。 使用する場合 Credential Passthrough と Meta インスタンスプロファイルを使用したクラスターでは、データ IAMロールのみを引き受けることができます。 アクセス。 これにより、異なるデータ アクセス ポリシーを持つ複数のユーザーが、データのセキュリティを確保しながら 1 つの Databricks クラスターを共有できます。
このセクションでは、IAM 認証情報のパススルーを有効にするために必要なメタインスタンスプロファイルの設定方法について説明します。
ステップ 1: IAM 認証情報のパススルーのロールを設定する
このセクションの内容:
データ IAMロールの作成
既存のデータIAM ロールを使用するか、必要に応じてチュートリアル「インスタンスプロファイルを使用して アクセスを構成する 」に従って、S3 バケットにアクセスできるデータIAM ロールを作成します。S3
メタ IAMロールの設定
メタ IAMロールを構成して、データ ロール IAM引き受けます。
-
AWSコンソールで、 [IAM] サービスに移動します。
-
サイドバーの「 ロール 」タブをクリックします。
-
「 ロールの作成 」をクリックします。
- [信頼できるエンティティの種類の選択] で、 [AWSサービス] を選択します。
- EC2 サービスをクリックします。
-
[次への権限] をクリックします。
-
「ポリシーの作成 」をクリックします。新しいウィンドウが開きます。
-
[JSON ] タブをクリックします。
-
次のポリシーをコピーし、
<account-id>を AWS アカウント ID に、<data-iam-role>を前のセクションのデータ IAMロールの名前に設定します。JSON{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AssumeDataRoles",
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": ["arn:aws:iam::<account-id>:role/<data-iam-role>"]
}
]
} -
「 ポリシーの確認 」をクリックします。
-
[名前] フィールドにポリシー名を入力し、[ ポリシーの作成 ] をクリックします。
-
-
ロールウィンドウに戻り、更新します。
-
ポリシー名を検索し、ポリシー名の横にあるチェックボックスをオンにします。
-
「次のタグ 」と 「次のレビュー 」をクリックします。
-
ロール名ファイルに、メタ IAMロールの名前を入力します。
-
「 ロールの作成 」をクリックします。
-
ロールの概要で、 インスタンスプロファイル ARN をコピーします。
メタIAMロールを信頼するようにデータIAMロールを構成する
メタ IAMロールがデータ IAMロールを引き継げるようにするには、メタロールをデータロールに信頼されるようにします。
-
AWSコンソールで、 [IAM] サービスに移動します。
-
サイドバーの「 ロール 」タブをクリックします。
-
前の手順で作成したデータ ロールを見つけてクリックし、ロールの詳細ページに移動します。
-
「信頼関係 」タブをクリックし、次のステートメントを追加していない場合は追加します。
JSON{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<account-id>:role/<meta-iam-role>"
},
"Action": "sts:AssumeRole"
}
]
}
ステップ 2: Databricks でメタインスタンスプロファイルを設定する
このセクションでは、 Databricksでメタ インスタンスプロファイルを設定する方法について説明します。
このセクションの内容:
- デプロイメントに使用されるIAM ロールを決定するDatabricks
- デプロイに使用する IAMロールのポリシー Databricks を変更します
- メタインスタンスプロファイルをDatabricksに追加する
デプロイメントに使用されるIAM ロールを決定するDatabricks
-
アカウントコンソールに移動します。
-
「ワークスペース」 アイコンをクリックします。
-
ワークスペースの名前をクリックします。
-
認証情報セクションの ARN キーの末尾にあるロール名をメモします (下の画像では [
testco-role] です。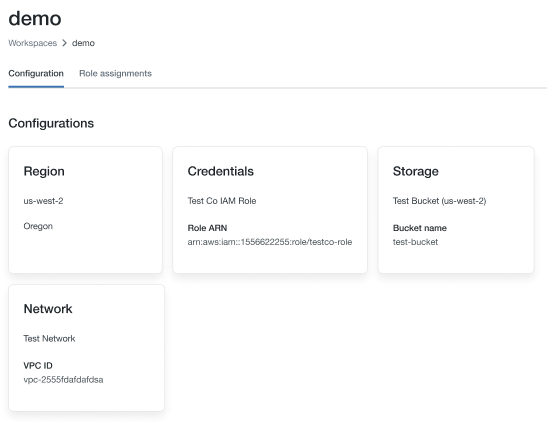
デプロイに使用する IAMロールのポリシー Databricks を変更します
- AWSコンソールで、 [IAM] サービスに移動します。
- サイドバーの「 ロール 」タブをクリックします。
- 前のセクションでメモしたロールを編集します。
- ロールにアタッチされているポリシーをクリックします。
- ポリシーを変更して、EC2 内のSpark クラスターのDatabricks インスタンスが、「IAMメタ ロールの設定 」で作成したメタインスタンスプロファイルを使用できるようにします。例については、「 ステップ 5: S3 IAMロールを EC2 ポリシーに追加する」を参照してください。
- 「ポリシーの確認 」をクリックし、「 変更を保存」をクリックします 。
メタインスタンスプロファイルをDatabricksに追加する
-
設定ページに移動します。
-
インスタンスプロファイル タブを選択します。
-
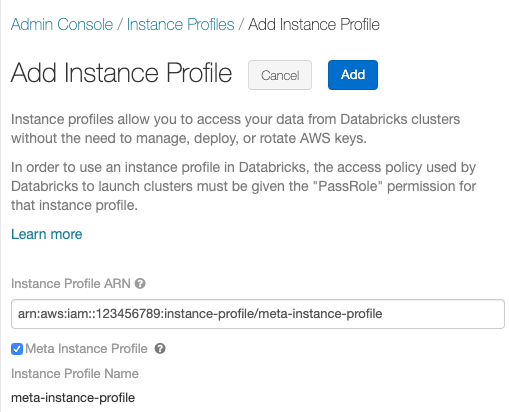
[ インスタンスプロファイルの追加 ]ボタンをクリックします。 ダイアログが表示されます。
-
メタ ロールの構成 からメタ ロールのインスタンスプロファイル ARNIAMIAMロールに貼り付けます。
-
「メタインスタンスプロファイル 」チェックボックスをオンにして、「 追加 」をクリックします。
-
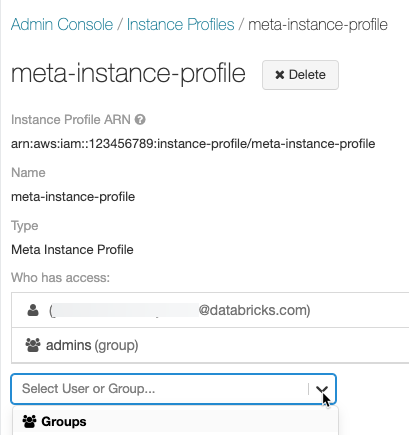
必要に応じて、メタ インスタンス プロファイルを使用してクラスターを起動できるユーザーを特定します。
ステップ 3: IAMロールのアクセス許可を Databricks ユーザーにアタッチする
IAMロールへのユーザーのマッピングを維持するには、次の 2 つの方法があります。
- Databricks 内で SCIM ユーザー API または SCIM グループ API を使用します。
- ID プロバイダー内。これにより、データ アクセスを一元化し、それらの権限をDatabricks SAML2.0 ID フェデレーションを介して クラスターに直接渡すことができます。
次の表を使用して、ワークスペースに適したマッピング方法を決定します。
要件 | SCIM | IDプロバイダー |
|---|---|---|
Databricks へのシングルサインオン | いいえ | あり |
AWS ID プロバイダーを構成する | いいえ | あり |
メタインスタンスプロファイルの構成 | あり | あり |
Databricks ワークスペース管理者 | あり | あり |
AWS管理者 | あり | あり |
ID プロバイダー管理者 | いいえ | あり |
メタ インスタンスプロファイルを使用してクラスターを開始すると、クラスターは ID を通過します また、アクセスできるデータ IAMロールのみを引き受けます。 管理者は、ユーザーに ロールIAMデータ・・ロールは、SCIM APIメソッドを使用してロールの権限を設定します。
IdP 内でロールをマッピングしている場合、それらのロールは SCIM 内でマッピングされたロールを上書きするため、ユーザーをロールに直接マッピングしないでください。 「手順 6: 必要に応じて、SAML から SCIM へのロール マッピングを同期するように Databricks を構成する」を参照してください。
また、 Databricks Terraform プロバイダー と databricks_user_role または グループを使用して、ユーザーまたはグループにインスタンスプロファイルをアタッチすることもできます。
IAM 資格情報パススルー クラスターを起動する
資格情報のパススルーを使用してクラスターを起動するプロセスは、クラスター モードによって異なります。
Enable credential passthrough for a High Concurrencyクラスター
High Concurrencyクラスターは、複数のユーザーで共有できます。 パススルー付きの Python と SQL のみをサポートします。
-
クラスターを作成するときは、 クラスターMode を高同時実行性に設定します。
-
Databricks Runtime バージョン 6.1 以降を選択します。
-
[詳細オプション ] で、[ ユーザーレベルのデータ アクセスの資格情報パススルーを有効にする] を選択し、Python コマンドと SQL コマンドのみを許可する を選択します。

-
「インスタンス」 タブをクリックします。 インスタンスプロファイル ドロップダウンで、 メタインスタンスプロファイルを Databricksに追加するで作成したメタインスタンスプロファイルを選択します。
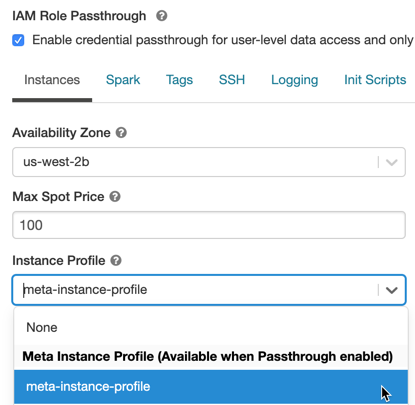
Standard クラスターの IAM 資格情報パススルーを有効にする
資格情報のパススルーを使用した Standard クラスターがサポートされており、1 人のユーザーに制限されています。 Standard クラスターでは、 Python、 SQL、 Scala、R がサポートされています。 Databricks Runtime 10.4 LTS 以降では、Sparklyr もサポートされています。
クラスターの作成時にユーザーを割り当てる必要がありますが、 CAN MANAGE 権限を持つユーザーはいつでもクラスターを編集して、元のユーザーを置き換えることができます。
クラスターに割り当てられたユーザーが、クラスターでコマンドを実行するには、クラスターに対する少なくとも Can Attach To つのアクセス許可が必要です。 ワークスペース 管理者とクラスター作成者には CAN MANAGE 権限がありますが、指定されたクラスター ユーザーでない限り、クラスターでコマンドを実行することはできません。
-
クラスターを作成するときは、 クラスターMode を Standard に設定します。
-
Databricks Runtime バージョン 6.1 以降を選択します。
-
[詳細オプション ] で、[ ユーザー レベルのデータ アクセスの資格情報パススルーを有効にする ] を選択します。
-
[シングル ユーザー アクセス ] ドロップダウンからユーザー名を選択します。
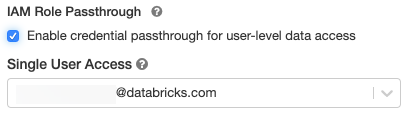
-
「インスタンス」 タブをクリックします。 インスタンスプロファイル のドロップダウンで、 メタインスタンスプロファイルを Databricksに追加するで作成したメタインスタンスプロファイルを選択します。
IAM 認証情報のパススルーを使用した S3 へのアクセス
S3 にアクセスするには、ロールを引き受けて S3 に直接アクセスするか、ロールを使用して S3 バケットをマウントし、マウントを通じてデータにアクセスすることで、認証情報のパススルーを使用します。
資格情報パススルーを使用した S3 データの読み取りと書き込み
S3 との間でデータの読み取りと書き込みを行います。
- Python
- R
dbutils.credentials.assumeRole("arn:aws:iam::xxxxxxxx:role/<data-iam-role>")
spark.read.format("csv").load("s3a://prod-foobar/sampledata.csv")
spark.range(1000).write.mode("overwrite").save("s3a://prod-foobar/sampledata.parquet")
dbutils.credentials.assumeRole("arn:aws:iam::xxxxxxxx:role/<data-iam-role>")
# SparkR
library(SparkR)
sparkR.session()
read.df("s3a://prod-foobar/sampledata.csv", source = "csv")
write.df(as.DataFrame(data.frame(1:1000)), path="s3a://prod-foobar/sampledata.parquet", source = "parquet", mode = "overwrite")
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("s3a://prod-foobar/sampledata.csv")
sc %>% sdf_len(1000) %>% spark_write_parquet("s3a://prod-foobar/sampledata.parquet", mode = "overwrite")
ロールで dbutils を使用します。
- Python
- R
dbutils.credentials.assumeRole("arn:aws:iam::xxxxxxxx:role/<data-iam-role>")
dbutils.fs.ls("s3a://bucketA/")
dbutils.credentials.assumeRole("arn:aws:iam::xxxxxxxx:role/<data-iam-role>")
dbutils.fs.ls("s3a://bucketA/")
その他の dbutils.credentials 方法については、 資格情報ユーティリティ (dbutils.credentials)を参照してください。
IAM 認証情報のパススルーを使用して S3 バケットを DBFS にマウントする
異なるバケットまたはプレフィックスが異なるロールを必要とするより高度なシナリオでは、 Databricks バケット マウントを使用して、特定の バケットパス。
IAM credential passthrough で有効になっているクラスターを使用してデータをマウントすると、 マウント・ポイントは、ユーザーの資格情報を使用してマウント・ポイントに対する認証を行います。このマウントポイントは次のようになります 他のユーザーには表示されますが、読み取りと書き込みのアクセス権を持つのは、次のユーザーのみです。
- IAM データロールを介して基盤となる S3 ストレージアカウントにアクセスできる
- IAM資格情報のパススルーに対して有効になっているクラスターを使用している
dbutils.fs.mount(
"s3a://<s3-bucket>/data/confidential",
"/mnt/confidential-data",
extra_configs = {
"fs.s3a.credentialsType": "Custom",
"fs.s3a.credentialsType.customClass": "com.databricks.backend.daemon.driver.aws.AwsCredentialContextTokenProvider",
"fs.s3a.stsAssumeRole.arn": "arn:aws:iam::xxxxxxxx:role/<confidential-data-role>"
})
IAM 認証情報のパススルーを使用してジョブ内の S3 データにアクセスする
ジョブで資格情報のパススルーを使用してS3データにアクセスするには、クラスターを構成します 「新規または既存のクラスターを選択したときに IAM 資格情報パススルー クラスターを起動する」に従っています。
クラスターは、ジョブ所有者に付与された役割のみを引き受けます。 したがって、ロールがアクセス権限を持つ S3 データにのみアクセスできます。
IAM 認証情報パススルーを使用して JDBC または ODBC クライアントから S3 データにアクセスします
クライアントまたは S3クライアントを使用してIAM 資格情報パススルーを使用してJDBC ODBCIAMデータにアクセスするには、クラスターを構成します 「 資格情報パススルー クラスターを起動し 、クライアントでこのクラスターに接続する」に従っています。ザ クラスターは、接続しているユーザーに権限が付与されているロールのみを引き受けます アクセスするため、ユーザーがアクセス許可を持っている S3 データにのみアクセスできます。
SQL クエリでロールを指定するには、次の操作を行います。
SET spark.databricks.credentials.assumed.role=arn:aws:iam::XXXX:role/<data-iam-role>;
-- Access the bucket which <my-role> has permission to access
SELECT count(*) from csv.`s3://my-bucket/test.csv`;
既知の制限事項
次の機能は、IAM 認証情報のパススルーではサポートされていません。
-
%fs(代わりに、同等の dbutils.fs コマンドを使用してください)。 -
SparkContext (
sc) オブジェクトと SparkSession (spark) オブジェクトの次のメソッド:- 非推奨のメソッド。
addFile()やaddJar()など、管理者以外のユーザーが Scala のコードを呼び出すことができるメソッド。- S3 以外のファイルシステムにアクセスする任意の方法。
- 古い Hadoop API (
hadoopFile()とhadoopRDD())。 - ストリームの実行中にパススルーされた資格情報の有効期限が切れるため、ストリーミング API。
-
DBFS マウント (
/dbfs) は、Databricks Runtime 7.3 LTS 以降でのみ使用できます。 資格情報のパススルーが構成されたマウント ポイントは、このパスではサポートされません。 -
クラスター全体のライブラリで、ダウンロードするにはクラスター インスタンスプロファイルのアクセス許可が必要です。 DBFS パスを持つライブラリのみがサポートされています。
-
Databricks Connect高コンカレンシー クラスターの は、Databricks Runtime 7.3LTS 以降でのみ使用できます。