Realize seu próprio benchmarking LLM endpoint
Os tópicos descritos nesta página se aplicam a cargas de trabalho de Taxa de transferência de provisionamento que atendem a modelos que provisionam a capacidade de inferência com base em tokens por segundo . Os seguintes modelos se aplicam:
- Meta Llama 3.3
- Meta Llama 3.2 3B
- Meta Llama 3.2 1B
- Meta Llama 3.1
- GTE v1.5 (inglês)
- BGE v1.5 (inglês)
- DeepSeek R1 (não disponível no Unity Catalog)
- Meta Llama 3
- Meta Llama 2
- DBRX
- Mistral
- Mixtral
- MPT
Consulte Unidades de modelo em provisionamento Taxa de transferência para modelos suportados que usam unidades de modelo (não tokens por segundo) para provisionamento de capacidade de inferência.
Este artigo fornece um exemplo de Notebook recomendado Databricks para avaliar o desempenho de um LLM endpoint. Ele também inclui uma breve introdução sobre como o site Databricks realiza a inferência LLM e calcula a latência e a Taxa de transferência como endpoint desempenho métricas.
A inferência LLM no Databricks mede tokens por segundo para o modo de provisionamento Taxa de transferência para APIs do Foundation Model. Veja modelos legados de provisionamento de Taxa de transferência implantados.
Exemplo de Benchmarking Notebook
O senhor pode importar o seguinte Notebook para o seu ambiente Databricks e especificar o nome do seu LLM endpoint para executar um teste de carga.
Benchmarking em LLM endpoint
Introdução à inferência LLM
Os LLMs realizam inferência em um processo de duas etapas:
- Preenchimento prévio , em que os tokens no prompt de entrada são processados em paralelo.
- Decodificação , em que o texto é gerado um token por vez de forma auto-regressiva. Cada token gerado é anexado à entrada e alimentado novamente no modelo para gerar os próximos tokens. A geração é interrompida quando o site LLM emite tokens de parada especiais ou quando uma condição definida pelo usuário é atendida.
A maioria dos aplicativos de produção tem um orçamento de latência, e o site Databricks recomenda que o senhor maximize a taxa de transferência com base nesse orçamento de latência.
- O número de tokens de entrada tem um impacto substancial sobre a memória necessária para processar solicitações.
- O número de tokens de saída domina a latência geral da resposta.
Databricks divide a inferência LLM nas seguintes sub-métricas:
- Tempo para os primeiros tokens (TTFT): É a rapidez com que os usuários começam a ver o resultado do modelo depois de inserir a consulta. Baixos tempos de espera por uma resposta são essenciais em interações em tempo real, mas menos importantes em cargas de trabalho off-line. Essa métrica é determinada pelo tempo necessário para processar o prompt e, em seguida, gerar os primeiros tokens de saída.
- Tempo por tokens de saída (TPOT): tempo para gerar tokens de saída para cada usuário que está consultando o sistema. Essa métrica corresponde à forma como cada usuário percebe a "velocidade" do modelo. Por exemplo, um TPOT de 100 milissegundos por tokens seria 10 tokens por segundo, ou ~450 palavras por minuto, o que é mais rápido do que uma pessoa comum consegue ler.
Com base nessas métricas, a latência total e a taxa de transferência podem ser definidas da seguinte forma:
- Latência = TTFT + (TPOT) * (o número de tokens a serem gerados)
- Taxa de transferência = número de tokens de saída por segundo em todas as solicitações de simultaneidade
Em Databricks, o endpoint de atendimento LLM é capaz de escalonar para corresponder à carga enviada por clientes com várias solicitações concorrente. Há uma compensação entre a latência e a taxa de transferência. Isso ocorre porque, no endpoint de atendimento LLM, as solicitações de concorrente podem ser e são processadas ao mesmo tempo. Em cargas de solicitação de baixa concorrência, a latência é a mais baixa possível. No entanto, se o senhor aumentar a carga de solicitações, a latência poderá aumentar, mas a Taxa de transferência provavelmente também aumentará. Isso ocorre porque duas solicitações de tokens por segundo podem ser processadas em menos do dobro do tempo.
Portanto, controlar o número de solicitações paralelas em seu sistema é fundamental para equilibrar a latência com a Taxa de transferência. Se o senhor tiver um caso de uso de baixa latência, deverá enviar menos solicitações de concorrente para o site endpoint para manter a latência baixa. Se o senhor tiver um caso de uso com alta taxa de transferência, vai querer saturar o site endpoint com muitas solicitações de simultaneidade, já que uma taxa de transferência mais alta vale a pena, mesmo às custas da latência.
- Os casos de uso de alta taxa de transferência podem incluir inferências de lotes e outras tarefas não voltadas para o usuário.
- Os casos de uso de baixa latência podem incluir aplicativos em tempo real que exigem respostas imediatas.
Arnês de benchmarking da Databricks
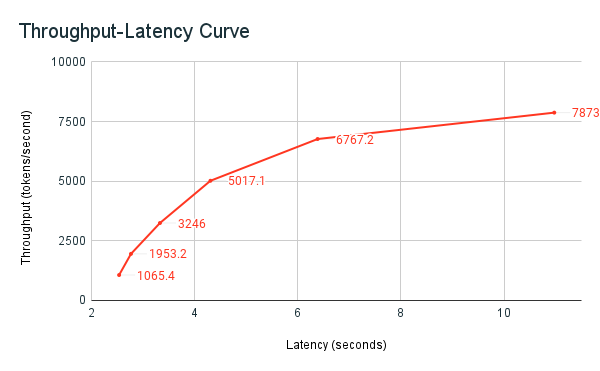
O exemplo de benchmarking compartilhado anteriormente, o Notebook, é o Databricks equipamento de benchmarking. O Notebook exibe a latência total em todas as solicitações e Taxa de transferência métricas e graficar a curva Taxa de transferência versus latência em diferentes números de solicitações paralelas. Databricks endpoint A estratégia de autoescala equilibra a latência e a taxa de transferência. No Notebook, o senhor observa que a latência e a taxa de transferência aumentam à medida que mais usuários concorrentes consultam o site endpoint.
No entanto, o senhor também começa a ver que, à medida que o número de solicitações paralelas aumenta, a taxa de transferência começa a se estabilizar, atingindo um limite de cerca de 8.000 tokens por segundo. Esse patamar ocorre porque o provisionamento Taxa de transferência para o site endpoint limita o número de solicitações paralelas e de trabalhadores que podem ser feitas. À medida que mais solicitações são feitas além do que o site endpoint pode processar simultaneamente, a latência total continua a aumentar à medida que solicitações adicionais aguardam na fila.
Mais detalhes sobre a filosofia do Databricks sobre LLM desempenho benchmarking estão descritos nos blogsLLM Inference desempenho engenharia: Best Practices.