What is Unity Catalog?
Unity Catalog is the unified governance layer for data and AI built into Databricks. When enabled for a workspace, Unity Catalog operates beneath every data and AI interaction in your workspaces automatically: enforcing access control when you query a table or call a model, tracking lineage as data and AI assets are used, logging activity for auditing, and more. You work with the objects Unity Catalog governs through Catalog Explorer, SQL, the Databricks CLI, and REST APIs.
Unity Catalog is automatically enabled for all Databricks workspaces created after November 8, 2023.
- To verify that Unity Catalog is enabled and set up properly for your workspace, see Unity Catalog setup guide.
- If your workspace was created before November 8, 2023, see Upgrade a Databricks workspace to Unity Catalog.
Unity Catalog is also available as an open-source implementation. See the announcement blog and the public Unity Catalog GitHub repo.
The Unity Catalog object model
Every asset you govern in Unity Catalog is modeled as a securable object, an object on which you can grant permissions to users, service principals, or groups. Data and AI assets such as tables, views, volumes, functions, models, and services (model services and MCP services) follow a three-level namespace (catalog.schema.object). Tables and volumes can be managed, where Unity Catalog handles both governance and the underlying file storage lifecycle, or external, where Unity Catalog handles governance only. Other objects, such as storage credentials, external locations, connections, and shares, sit directly under the metastore.
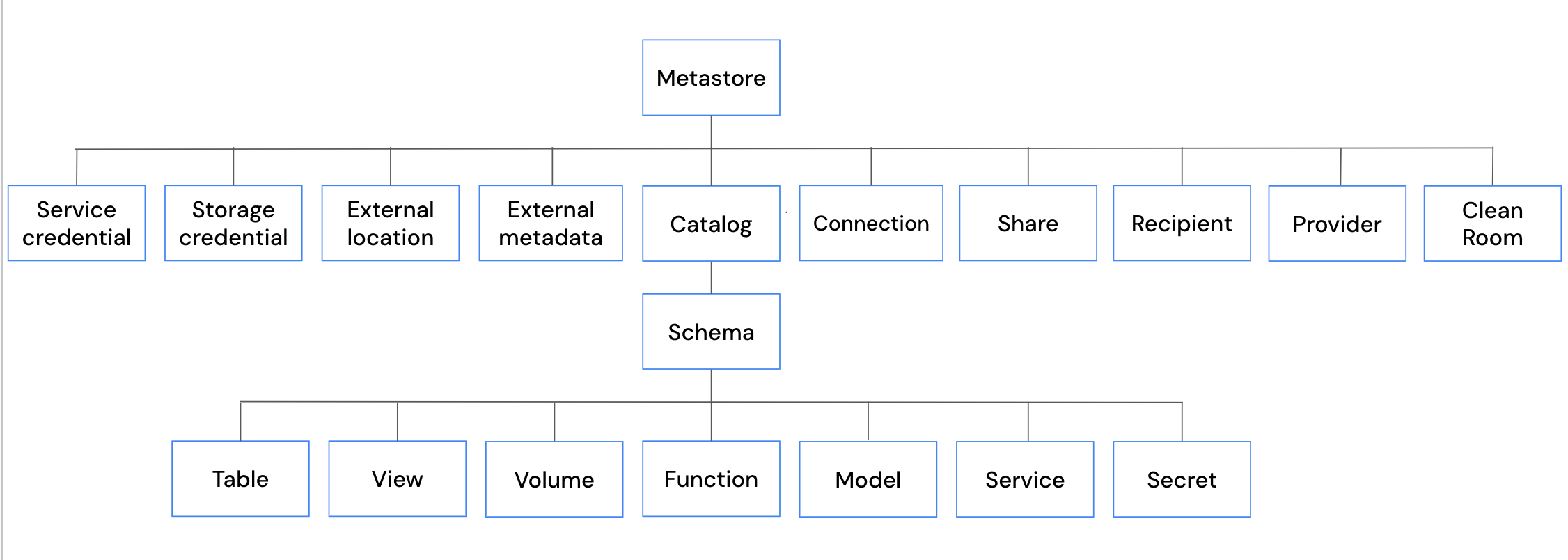
The following pages explain core Unity Catalog concepts and workflows in more detail.
-
- Securable objects
- Learn about each object type in the Unity Catalog hierarchy and how permissions apply to them.
-
- Managed versus external assets
- Understand the difference between managed and external tables and volumes, and when to use each.
-
- Requirements and limitations
- Review compute requirements, supported file formats, naming constraints, and known limitations.
Unity Catalog capabilities
Unity Catalog provides built-in tools for governing every dimension of your data and AI environment. The following topics cover the major capability areas.
-
- Access control
- Manage who can access what using privileges, attribute-based policies, row and column filters, and workspace bindings.
-
- Discovery
- Interact with securable objects using Catalog Explorer, the Databricks UI for discovering and managing data and AI assets registered in Unity Catalog.
-
- Lineage
- Automatically track how data and AI assets flow and connect, from source data through to models, services, and dashboards.
-
- Auditing
- Maintain a complete record of all data access and system activity using the audit log system table.
-
- Data classification
- Automatically classify and tag sensitive data in your catalog.
-
- Data quality monitoring
- Proactively track data health with built-in profiling and alerts that catch anomalies before they reach downstream consumers.
-
- Data sharing
- Securely share live data and AI assets across organizations and clouds using the open OpenSharing protocol.
-
- AI governance
- Govern AI assets and AI traffic using Unity Catalog and AI Gateway.
Get started
The following resources help you get started with Unity Catalog. If your workspace was created after November 8, 2023, it is automatically enabled with Unity Catalog.
-
- Get started with Unity Catalog
- Check if Unity Catalog is already enabled for your workspace, and configure your first catalog, schema, and data access controls.
-
- Upgrade to Unity Catalog
- Learn how to upgrade a workspace that is not yet using Unity Catalog.
-
- AI governance guide
- Set up governance for your AI assets, AI traffic, and AI service behavior.