Use AWS Glue catálogo de dados como um metastore (legado)
Essa documentação foi descontinuada e pode não estar atualizada.
O uso de metastores externos é um modelo de governança de dados legado. A Databricks recomenda que o senhor atualize para o Unity Catalog. Unity Catalog simplifica a segurança e a governança de seus dados, fornecendo um local central para administrar e auditar o acesso aos dados em vários espaços de trabalho em seu site account. Consulte O que é o Unity Catalog?
O senhor pode configurar o Databricks Runtime para usar o AWS Glue catálogo de dados como metastore. Ele pode servir como um substituto para um Hive metastore.
Cada AWS account possui um único catálogo em uma região AWS cujo ID do catálogo é o mesmo que o ID AWS account . O uso do Glue Catalog como metastore para Databricks pode potencialmente permitir um metastore compartilhado entre AWS serviços, aplicativos ou AWS contas.
O senhor pode configurar vários espaços de trabalho do Databricks para compartilhar o mesmo metastore.
Este artigo mostra como acessar com segurança um catálogo de dados Glue em Databricks usando o perfil de instância.
Requisitos
- O senhor deve ter acesso de administrador AWS à função e às políticas IAM no site AWS account onde Databricks está implantado e no site AWS account que contém o catálogo de dados Glue.
- Se o Glue catálogo de dados estiver em um AWS account diferente de onde o Databricks está implantado, uma política de acesso cruzadoaccount deverá permitir o acesso ao catálogo do AWS account onde o Databricks está implantado. Observe que só suportamos a concessão de acesso entreaccount usando uma política de recurso para Glue.
- O modo integrado requer Databricks Runtime 8.4 ou acima, ou Databricks Runtime 7.3 LTS.
Configurar o Glue catálogo de dados como metastore
Para ativar a integração do Glue Catalog, defina a configuração do Spark spark.databricks.hive.metastore.glueCatalog.enabled true. Essa configuração é desativada pelo site default. Ou seja, o default deve usar o Databricks hospedado no Hive metastore, ou algum outro metastore externo, se configurado.
Para clustering interativo ou de trabalho, defina a configuração na configuração de clustering antes de fazer o clustering startup.
Essa opção de configuração não pode ser modificada em um cluster em execução.
Ao executar o trabalho spark-submit, defina essa opção de configuração nos parâmetros spark-submit usando --conf spark.databricks.hive.metastore.glueCatalog.enabled=true ou defina-a no código antes de criar o SparkSession ou SparkContext. Por exemplo:
from pyspark.sql import SparkSession
# Set the Glue confs here directly instead of using the --conf option in spark-submit
spark = SparkSession.builder. \
appName("ExamplePySparkSubmitTask"). \
config("spark.databricks.hive.metastore.glueCatalog.enabled", "true"). \
enableHiveSupport(). \
getOrCreate()
print(spark.sparkContext.getConf().get("spark.databricks.hive.metastore.glueCatalog.enabled"))
spark.sql("show databases").show()
spark.stop()
A forma como o senhor configura o acesso ao Glue Catalog depende do fato de o Databricks e o Glue Catalog estarem na mesma AWS account e região, em contas diferentes ou em regiões diferentes. Siga as etapas apropriadas no restante deste artigo:
- O mesmo AWS account e região : Siga a etapa 1 e, em seguida, as etapas 3 a 5.
- Cruzamento -account : Siga as etapas de 1 a 6.
- Entre regiões : siga a etapa 1 e depois as etapas 3 a 6.
As políticas do AWS Glue catálogo de dados definem apenas as permissões de acesso aos metadados. As políticas S3 definem as permissões de acesso ao próprio conteúdo. Essas etapas configuram uma política no site AWS Glue catálogo de dados. Eles não configuram o bucket S3 relacionado ou as políticas de nível de objeto. Veja o tutorial: Configurar o acesso S3 com um instance profile para configurar as permissões S3 para Databricks.
Para obter mais informações, consulte Restringir o acesso ao seu AWS Glue catálogo de dados com permissões IAM em nível de recurso e políticas baseadas em recurso.
Etapa 1: Crie um instance profile para acessar um Glue catálogo de dados
-
No console do AWS, acesse o serviço IAM.
-
Clique em Roles (Funções) tab na barra lateral.
-
Clique em Criar função .
-
Em Select type of trusted entity (Selecionar tipo de entidade confiável), selecione AWS serviço .
-
Clique no serviço EC2 .
-
Em Selecione seu caso de uso, clique em EC2 .
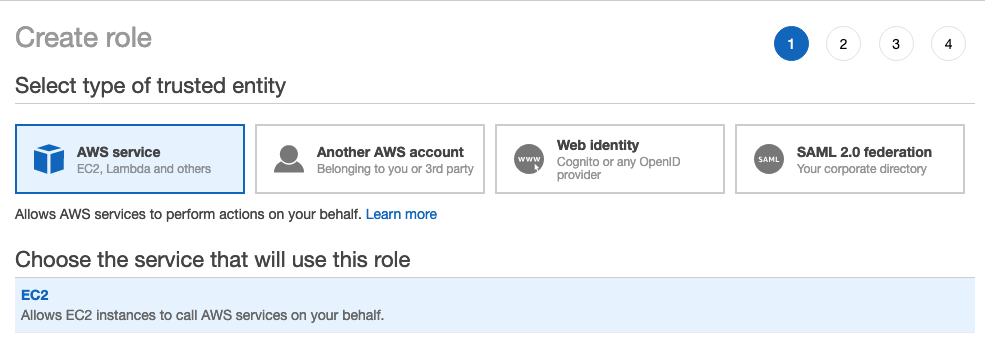
-
Clique em Avançar: Permissões e clique em Avançar: Revisão .
-
No campo Nome da função, digite um nome da função.
-
Clique em Criar papel . A lista de funções é exibida.
-
-
Na lista de funções, clique na função.
-
Adicionar uma política em linha ao Glue Catalog.
-
Em Permissions (Permissões) tab, clique em
 .
. -
Clique no botão JSON tab.
-
Copie e cole esta política no site tab.
JSON{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "GrantCatalogAccessToGlue",
"Effect": "Allow",
"Action": [
"glue:BatchCreatePartition",
"glue:BatchDeletePartition",
"glue:BatchGetPartition",
"glue:CreateDatabase",
"glue:CreateTable",
"glue:CreateUserDefinedFunction",
"glue:DeleteDatabase",
"glue:DeletePartition",
"glue:DeleteTable",
"glue:DeleteUserDefinedFunction",
"glue:GetDatabase",
"glue:GetDatabases",
"glue:GetPartition",
"glue:GetPartitions",
"glue:GetTable",
"glue:GetTables",
"glue:GetUserDefinedFunction",
"glue:GetUserDefinedFunctions",
"glue:UpdateDatabase",
"glue:UpdatePartition",
"glue:UpdateTable",
"glue:UpdateUserDefinedFunction"
],
"Resource": "arn:aws:glue:<aws-region-target-glue-catalog>:<aws-account-id-target-glue-catalog>:*",
"Condition": {
"ArnEquals": {
"aws:PrincipalArn": ["arn:aws:iam::<aws-account-id-databricks>:role/<iam-role-for-glue-access>"]
}
}
}
]
}
-
Para obter uma configuração detalhada dos recursos permitidos (catálogo, banco de dados, tabela, userDefinedFunction), consulte Especificação de AWS Glue recurso ARNs.
Se a lista de ações permitidas na política acima for insuficiente, entre em contato com o suporte Databricks com as informações sobre o erro. A solução mais simples é usar uma política que dê acesso total ao Glue:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "GrantFullAccessToGlue",
"Effect": "Allow",
"Action": ["glue:*"],
"Resource": "*"
}
]
}
Etapa 2: criar uma política para o Glue Catalog de destino
Siga esta etapa somente se o catálogo de destino Glue estiver em um AWS accountdiferente do usado para a implementação Databricks.
-
Faça login no AWS account do Catálogo Glue de destino e acesse o Console Glue.
-
Em Configurações, cole a política a seguir na caixa Permissões. Defina
<aws-account-id-databricks>,<iam-role-for-glue-access>a partir da Etapa 1,<aws-region-target-glue-catalog>,<aws-account-id-target-glue-catalog>, adequadamente.JSON{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Example permission",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<aws-account-id-databricks>:role/<iam-role-for-glue-access>"
},
"Action": [
"glue:BatchCreatePartition",
"glue:BatchDeletePartition",
"glue:BatchGetPartition",
"glue:CreateDatabase",
"glue:CreateTable",
"glue:CreateUserDefinedFunction",
"glue:DeleteDatabase",
"glue:DeletePartition",
"glue:DeleteTable",
"glue:DeleteUserDefinedFunction",
"glue:GetDatabase",
"glue:GetDatabases",
"glue:GetPartition",
"glue:GetPartitions",
"glue:GetTable",
"glue:GetTables",
"glue:GetUserDefinedFunction",
"glue:GetUserDefinedFunctions",
"glue:UpdateDatabase",
"glue:UpdatePartition",
"glue:UpdateTable",
"glue:UpdateUserDefinedFunction"
],
"Resource": "arn:aws:glue:<aws-region-target-glue-catalog>:<aws-account-id-target-glue-catalog>:*"
}
]
}
Etapa 3: Procure o site IAM role usado para criar a implantação do Databricks
Este IAM role é a função que o senhor usou quando configurou o Databricks account.
As etapas a seguir são diferentes para uma conta na versão E2 da plataforma e para uma conta em outra versão da plataforma Databricks. Todas as novas contas Databricks e a maioria das contas existentes agora são E2.
Se o senhor estiver em um E2 account:
-
Como account proprietário ou administradorlog in da conta, acesse account o console em.
-
Acesse Workspaces e clique no nome do seu workspace.
-
Na caixa Credenciais , anote o nome da função no final do ARN da Função.
Por exemplo, em Role ARN
arn:aws:iam::123456789123:role/finance-prod, finance-prod é o nome da função.
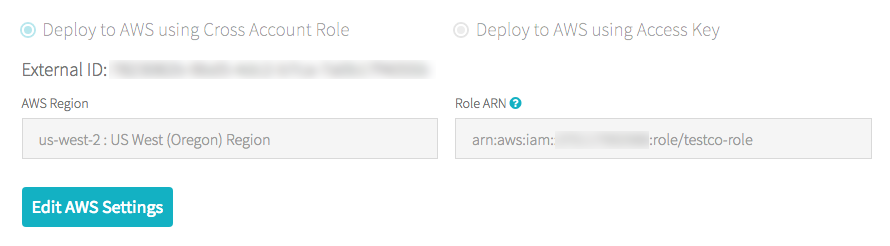
Se o senhor não estiver em um E2 account:
-
Como proprietário do account, acesse log in no consoleaccount.
-
Clique na contaAWS tab.
-
Observe o nome da função no final do ARN da função, aqui testco-role .
Etapa 4: Adicionar o catálogo Glue instance profile à política EC2
-
No console do AWS, acesse o serviço IAM.
-
Clique na guia Funções na barra lateral.
-
Clique na função que você anotou na Etapa 3.
-
Em Permissions (Permissões) tab, clique na política.
-
Clique em Editar política .
-
Modifique a política para permitir que Databricks passe a instance profile que o senhor criou na Etapa 1 para as instâncias de EC2 para o clustering de Spark. Aqui está um exemplo de como deve ser a nova política. Substitua
<iam-role-for-glue-access>pela função que você criou na Etapa 1.-
Para contas na versão E2 da plataforma:
JSON{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1403287045000",
"Effect": "Allow",
"Action": [
"ec2:AssociateDhcpOptions",
"ec2:AssociateIamInstanceProfile",
"ec2:AssociateRouteTable",
"ec2:AttachInternetGateway",
"ec2:AttachVolume",
"ec2:AuthorizeSecurityGroupEgress",
"ec2:AuthorizeSecurityGroupIngress",
"ec2:CancelSpotInstanceRequests",
"ec2:CreateDhcpOptions",
"ec2:CreateInternetGateway",
"ec2:CreatePlacementGroup",
"ec2:CreateRoute",
"ec2:CreateSecurityGroup",
"ec2:CreateSubnet",
"ec2:CreateTags",
"ec2:CreateVolume",
"ec2:CreateVpc",
"ec2:CreateVpcPeeringConnection",
"ec2:DeleteInternetGateway",
"ec2:DeletePlacementGroup",
"ec2:DeleteRoute",
"ec2:DeleteRouteTable",
"ec2:DeleteSecurityGroup",
"ec2:DeleteSubnet",
"ec2:DeleteTags",
"ec2:DeleteVolume",
"ec2:DeleteVpc",
"ec2:DescribeAvailabilityZones",
"ec2:DescribeIamInstanceProfileAssociations",
"ec2:DescribeInstanceStatus",
"ec2:DescribeInstances",
"ec2:DescribePlacementGroups",
"ec2:DescribePrefixLists",
"ec2:DescribeReservedInstancesOfferings",
"ec2:DescribeRouteTables",
"ec2:DescribeSecurityGroups",
"ec2:DescribeSpotInstanceRequests",
"ec2:DescribeSpotPriceHistory",
"ec2:DescribeSubnets",
"ec2:DescribeVolumes",
"ec2:DescribeVpcs",
"ec2:DetachInternetGateway",
"ec2:DisassociateIamInstanceProfile",
"ec2:ModifyVpcAttribute",
"ec2:ReplaceIamInstanceProfileAssociation",
"ec2:RequestSpotInstances",
"ec2:RevokeSecurityGroupEgress",
"ec2:RevokeSecurityGroupIngress",
"ec2:RunInstances",
"ec2:TerminateInstances"
],
"Resource": ["*"]
},
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::<aws-account-id-databricks>:role/<iam-role-for-glue-access>"
}
]
}- Para contas em outras versões da plataforma:
JSON{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1403287045000",
"Effect": "Allow",
"Action": [
"ec2:AssociateDhcpOptions",
"ec2:AssociateIamInstanceProfile",
"ec2:AssociateRouteTable",
"ec2:AttachInternetGateway",
"ec2:AttachVolume",
"ec2:AuthorizeSecurityGroupEgress",
"ec2:AuthorizeSecurityGroupIngress",
"ec2:CancelSpotInstanceRequests",
"ec2:CreateDhcpOptions",
"ec2:CreateInternetGateway",
"ec2:CreateKeyPair",
"ec2:CreateRoute",
"ec2:CreateSecurityGroup",
"ec2:CreateSubnet",
"ec2:CreateTags",
"ec2:CreateVolume",
"ec2:CreateVpc",
"ec2:CreateVpcPeeringConnection",
"ec2:DeleteInternetGateway",
"ec2:DeleteKeyPair",
"ec2:DeleteRoute",
"ec2:DeleteRouteTable",
"ec2:DeleteSecurityGroup",
"ec2:DeleteSubnet",
"ec2:DeleteTags",
"ec2:DeleteVolume",
"ec2:DeleteVpc",
"ec2:DescribeAvailabilityZones",
"ec2:DescribeIamInstanceProfileAssociations",
"ec2:DescribeInstanceStatus",
"ec2:DescribeInstances",
"ec2:DescribePrefixLists",
"ec2:DescribeReservedInstancesOfferings",
"ec2:DescribeRouteTables",
"ec2:DescribeSecurityGroups",
"ec2:DescribeSpotInstanceRequests",
"ec2:DescribeSpotPriceHistory",
"ec2:DescribeSubnets",
"ec2:DescribeVolumes",
"ec2:DescribeVpcs",
"ec2:DetachInternetGateway",
"ec2:DisassociateIamInstanceProfile",
"ec2:ModifyVpcAttribute",
"ec2:ReplaceIamInstanceProfileAssociation",
"ec2:RequestSpotInstances",
"ec2:RevokeSecurityGroupEgress",
"ec2:RevokeSecurityGroupIngress",
"ec2:RunInstances",
"ec2:TerminateInstances"
],
"Resource": ["*"]
},
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::<aws-account-id-databricks>:role/<iam-role-for-glue-access>"
}
]
}
-
-
Clique em Revisar política .
-
Clique em Salvar alterações .
Etapa 5: Adicionar o catálogo Glue instance profile a um Databricks workspace
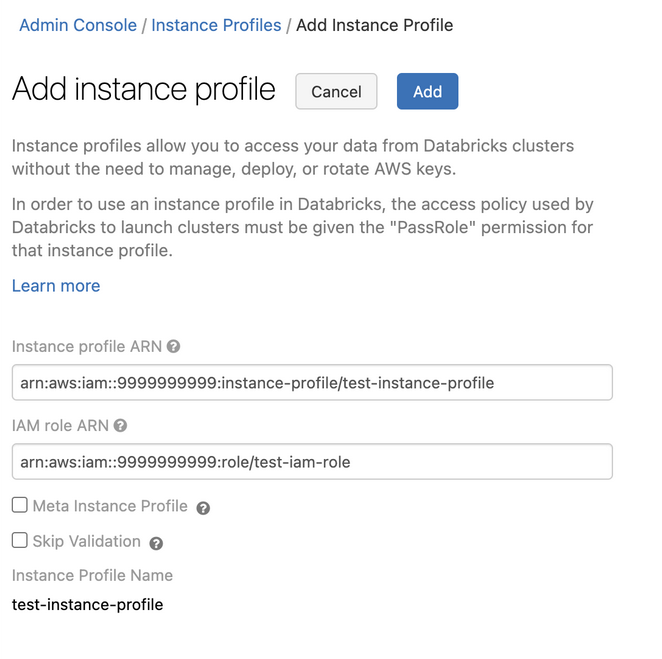
-
Ir para a página Configurações do administrador.
-
Clique na guia Instance profiles .
-
Clique no botão Add instance profile (Adicionar perfil de instância ). Uma caixa de diálogo é exibida.
-
Cole o perfil da instância ARN da Etapa 1.
Databricks valida que esse perfil de instância ARN está sintática e semanticamente correto. Para validar a exatidão semântica, o site Databricks faz uma execução seca, lançando um clustering com este instance profile. Qualquer falha nessa execução seca produz um erro de validação na interface do usuário.
A validação do instance profile pode falhar se ele contiver a política de aplicação de tags, impedindo que o senhor adicione um instance profile legítimo. Se a validação falhar e o senhor ainda quiser adicionar o instance profile a Databricks, use o perfil de instância API e especifique skip_validation.
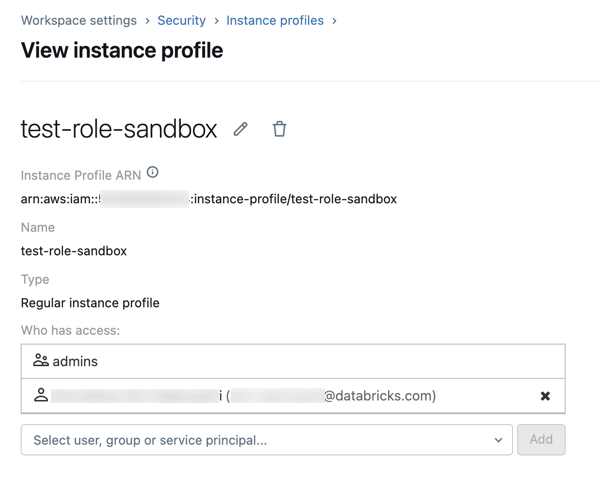
-
Clique em Adicionar .
-
Opcionalmente, especifique os usuários que podem iniciar o clustering com o endereço instance profile.
Etapa 6: Iniciar um clustering com o catálogo Glue instance profile
-
Criar um clustering.
-
Clique em Instâncias tab na página de criação de clustering.
-
Na lista suspensa do perfil da instância , selecione instance profile.
-
Verifique se o senhor pode acessar o Catálogo Glue usando o seguinte comando em um Notebook:
SQLshow databases;Se o comando for bem-sucedido, esse clustering Databricks Runtime será configurado para usar Glue. Dependendo da sua região AWS account e Glue, talvez seja necessário executar duas etapas adicionais:
-
Se o AWS account da implantação Databricks e o AWS account do Glue catálogo de dados forem diferentes, será necessária uma configuração cruzada extraaccount.
Defina
spark.hadoop.hive.metastore.glue.catalogid <aws-account-id-for-glue-catalog>na configuração do Spark. -
Se o Glue Catalog de destino estiver em uma região diferente da implantação do Databricks, especifique também
spark.hadoop.aws.region <aws-region-for-glue-catalog>.
-
Um lembrete de que spark.databricks.Hive metastore.glueCatalog.enabled true é uma configuração necessária para a conexão com AWS Glue.
-
Spark inclui suporte integrado para Hive, mas a utilização desse suporte depende da versão do Databricks Runtime.
- Modo de isolamento : o suporte integrado para Hive está desativado. biblioteca para Hive 1.2.1.spark2 são carregados a partir de
/databricks/glue/. No Databricks Runtime 8.3, o modo de isolamento está ativado e não pode ser desativado. Em Databricks Runtime 7.3 LTS e Databricks Runtime 8.4 e acima, o modo de isolamento é o default, mas pode ser desativado. - modo integrado : o suporte integrado para Hive está ativado e a versão Hive depende da versão Spark. Em Databricks Runtime 7.3 LTS e Databricks Runtime 8.4 e acima, o senhor pode ativar o modo integrado definindo
spark.databricks.hive.metastore.glueCatalog.isolation.enabled falseno clustering.
- Modo de isolamento : o suporte integrado para Hive está desativado. biblioteca para Hive 1.2.1.spark2 são carregados a partir de
-
Para ativar a passagem de credenciais, defina
spark.databricks.passthrough.enabled true. Isso requer Databricks Runtime 7.3 LTS ou Databricks Runtime 8.4 ou acima. Em Databricks Runtime 7.3 LTS e Databricks Runtime 8.4 e acima, essa configuração também ativa automaticamente o modo integrado.
Limitações
- O uso do AWS Glue catálogo de dados como metastore no Databricks tem a possibilidade de ter uma latência mais alta do que o default Hive metastore. Para obter mais informações, consulte Experiencing higher latency with Glue Catalog than Databricks Hive metastorena seção Troubleshooting (Solução de problemas).
- O banco de dados default é criado com um local definido para um URI usando o esquema
dbfs:(Databricks File System). Esse local não é acessível a partir de aplicativos AWS fora do Databricks, como o AWS EMR ou o AWS Athena. Como solução alternativa, use a cláusulaLOCATIONpara especificar a localização de um bucket, comos3://mybucket/, ao chamarCREATE TABLE. Como alternativa, crie tabelas em um banco de dados que não seja o default e defina oLOCATIONdesse banco de dados para um local S3. - O senhor não pode alternar dinamicamente entre o Glue Catalog e um Hive metastore. O senhor deve reiniciar o clustering para que as novas configurações do Spark entrem em vigor.
- A passagem de credenciais é suportada somente em Databricks Runtime 8.4 e acima.
- Os seguintes recursos não são suportados:
- Databricks Connect
- Interações entre sistemas em que você compartilha o mesmo catálogo de metadados ou dados reais da tabela em vários sistemas.
Ao especificar a localização de um esquema, você deve incluir uma barra final no URI, como s3://mybucket/ em vez de s3://mybucket. A omissão da barra pode resultar em exceções.
Solução de problemas
Nesta secção:
- Maior latência com o Glue Catalog do que com o Databricks Hive metastore
- Não há instance profile anexado ao clustering Databricks Runtime
- Insuficiente Glue Permissão do catálogo
- Erro de permissão em
glue:GetDatabaseao executar o SQL diretamente nos arquivos - Incompatibilidade Glue ID do catálogo
- Conflitos do Athena Catalog com o Glue Catalog
- Criando uma tabela em um banco de dados com espaço vazio
LOCATION - Acesso a tabelas entre o espaço de trabalho Databricks a partir de um catálogo Glue compartilhado
- Acesso a tabelas e visualizações criadas em outro sistema
Maior latência com o Glue Catalog do que com o Databricks Hive metastore
O uso do Glue catálogo de dados como metastore externo pode gerar uma latência maior do que o default Databricks hospedado Hive metastore. A Databricks recomenda ativar o cache do lado do cliente no cliente do Glue Catalog. As seções a seguir mostram como configurar o cache do lado do cliente para tabelas e bancos de dados. O senhor pode configurar o cache do lado do cliente para o armazenamento em cluster e SQL.
- O cache do lado do cliente não está disponível para as operações da tabela de listagem
getTables. - A configuração de tempo de vida útil (TTL) é uma compensação entre a eficácia do cache e a obsolescência tolerável dos metadados. Escolha um valor TTL que faça sentido para o cenário específico.
Para obter mais detalhes, consulte Ativação do cache do lado do cliente para o Glue Catalog na documentação do AWS.
Tabelas
spark.hadoop.aws.glue.cache.table.enable true
spark.hadoop.aws.glue.cache.table.size 1000
spark.hadoop.aws.glue.cache.table.ttl-mins 30
bancos de dados
spark.hadoop.aws.glue.cache.db.enable true
spark.hadoop.aws.glue.cache.db.size 1000
spark.hadoop.aws.glue.cache.db.ttl-mins 30
Não há instance profile anexado ao clustering Databricks Runtime
Se nenhum instance profile estiver anexado ao clustering Databricks Runtime, ocorrerá a seguinte exceção quando o senhor executar qualquer operação que exija a pesquisa de metastore:
org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: com.amazonaws.SdkClientException: Unable to load AWS credentials from any provider in the chain: [EnvironmentVariableCredentialsProvider: Unable to load AWS credentials from environment variables (AWS_ACCESS_KEY_ID (or AWS_ACCESS_KEY) and AWS_SECRET_KEY (or AWS_SECRET_ACCESS_KEY)), SystemPropertiesCredentialsProvider: Unable to load AWS credentials from Java system properties (aws.accessKeyId and aws.secretKey), com.amazonaws.auth.profile.ProfileCredentialsProvider@2245a35d: profile file cannot be null, com.amazonaws.auth.EC2ContainerCredentialsProviderWrapper@52be6b57: The requested metadata is not found at https://169.254.169.254/latest/meta-data/iam/security-credentials/];
Anexe um instance profile que tenha permissões suficientes para acessar o Catálogo Glue desejado.
Insuficiente Glue Permissão do catálogo
Quando o site instance profile não concede uma permissão necessária para executar uma operação de metastore, ocorre uma exceção como a seguinte:
org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: MetaException(message:Unable to verify existence of default database: com.amazonaws.services.glue.model.AccessDeniedException: User: arn:aws:sts::<aws-account-id>:assumed-role/<role-id>/... is not authorized to perform: glue:GetDatabase on resource: arn:aws:glue:<aws-region-for-glue-catalog>:<aws-account-id-for-glue-catalog>:catalog (Service: AWSGlue; Status Code: 400; Error Code: AccessDeniedException; Request ID: <request-id>));
Verifique se o site instance profile anexado especifica permissões suficientes. Por exemplo, na exceção anterior, adicione glue:GetDatabase ao endereço instance profile.
Erro de permissão em glue:GetDatabase ao executar o SQL diretamente nos arquivos
Nas versões do Databricks Runtime abaixo da 8.0, ao executar uma consulta SQL diretamente em arquivos, por exemplo,
select * from parquet.`path-to-data`
você pode encontrar um erro como o seguinte:
Error in SQL statement: AnalysisException ... is not authorized to perform: glue:GetDatabase on resource: <glue-account>:database/parquet
Isso acontece quando a política IAM não concede permissão para executar glue:GetDatabase no recurso database/<datasource-format>, em que <datasource-format> é um formato de fonte de dados, como parquet ou delta.
Adicione permissões à política de IAM para permitir glue:GetDatabase em database/<datasource-format>.
Há uma limitação na implementação do analisador Spark SQL, em que ele tenta resolver uma relação com o catálogo antes de voltar a tentar resolver com a fonte de dados registrada para SQL no arquivo. O fallback só funciona quando a tentativa inicial de resolução do catálogo retorna sem uma exceção.
Mesmo que o recurso database/<datasource-format> possa não existir, para que o fallback para a consulta SQL no arquivo seja executado com êxito, a política do IAM para o Glue Catalog deve permitir a execução da ação glue:GetDatabase nele.
Em Databricks Runtime 8.0 e acima, esse problema é tratado automaticamente e essa solução alternativa não é mais necessária.
Incompatibilidade Glue ID do catálogo
Em default, um clustering Databricks tenta se conectar ao catálogo Glue no mesmo AWS account que o usado para a implantação Databricks.
Se o Catálogo de destino Glue estiver em uma AWS account ou região diferente da implantação Databricks e a configuração spark.hadoop.hive.metastore.glue.catalogid Spark não estiver definida, o clustering se conectará ao Catálogo Glue na AWS account da implantação Databricks em vez do catálogo de destino.
Se a configuração spark.hadoop.hive.metastore.glue.catalogid estiver definida, mas as configurações na Etapa 2 não tiverem sido feitas corretamente, qualquer acesso ao metastore causará uma exceção como a seguinte:
org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: MetaException(message:Unable to verify existence of default database: com.amazonaws.services.glue.model.AccessDeniedException: User:
arn:aws:sts::<aws-account-id>:assumed-role/<role-id>/... is not authorized to perform: glue:GetDatabase on resource: arn:aws:glue:<aws-region-for-glue-catalog>:<aws-account-id-for-glue-catalog>:catalog (Service: AWSGlue; Status Code: 400; Error Code: AccessDeniedException; Request ID: <request-id>));
Verifique se a configuração está alinhada com as etapas 2 e 6 deste artigo.
Conflitos do Athena Catalog com o Glue Catalog
Se o senhor criou tabelas usando Amazon Athena ou Amazon Redshift Spectrum antes de 14 de agosto de 2017, os bancos de dados e as tabelas são armazenados em um catálogo Athena-gerenciar, que é separado do AWS Glue catálogo de dados. Para integrar o Databricks Runtime com essas tabelas, o senhor deve atualizar para o AWS Glue catálogo de dados. Caso contrário, o Databricks Runtime não conseguirá se conectar ao Glue Catalog ou não conseguirá criar e acessar alguns bancos de dados, e a mensagem de exceção poderá ser enigmática.
Por exemplo, se o banco de dados "default" existir no catálogo Athena, mas não no catálogo Glue, ocorrerá uma exceção com uma mensagem como
AWSCatalogMetastoreClient: Unable to verify existence of default database:
com.amazonaws.services.glue.model.AccessDeniedException: Please migrate your Catalog to enable access to this database (Service: AWSGlue; Status Code: 400; Error Code: AccessDeniedException; Request ID: <request-id>)
Siga as instruções em Upgrading to the AWS Glue catálogo de dados no Amazon Athena User guide.
Criando uma tabela em um banco de dados com espaço vazio LOCATION
Os bancos de dados do Glue Catalog podem ser criados a partir de várias fontes. Os bancos de dados criados por Databricks Runtime têm um campo LOCATION não vazio por default. Os bancos de dados criados diretamente no Console do Glue ou importados de outras fontes podem ter um campo LOCATION vazio.
Quando o Databricks Runtime tenta criar uma tabela em um banco de dados com um campo LOCATION vazio, ocorre uma exceção como a seguinte: like:
IllegalArgumentException: Can not create a Path from an empty string
Crie o banco de dados no Glue Catalog com um caminho válido e não vazio no campo LOCATION, especifique o LOCATION ao criar a tabela no SQL ou especifique option("path", <some-valid-path>) na API DataFrame.
Quando o senhor cria um banco de dados no Console do AWS Glue, apenas o nome é obrigatório; tanto a "Descrição" quanto a "Localização" são marcadas como opcionais. No entanto, as operações do Hive metastore dependem de "Location", portanto, o senhor deve especificá-lo para os bancos de dados que serão usados no Databricks Runtime.
Acesso a tabelas entre o espaço de trabalho Databricks a partir de um catálogo Glue compartilhado
A palavra-chave LOCATION pode ser definida em um nível de banco de dados (controlando o local default para todas as tabelas) ou como parte da instrução CREATE TABLE. Se o caminho especificado por LOCATION for um bucket montado, o senhor deverá usar o mesmo nome de montagem em todos os espaços de trabalho Databricks que compartilham o Catálogo Glue. Como o catálogo Glue armazena referências ao uso de dados no caminho especificado pelo valor LOCATION, o uso do mesmo nome de ponto de montagem garante que cada workspace possa acessar os objetos de banco de dados armazenados no bucket S3.
Acesso a tabelas e visualizações criadas em outro sistema
O acesso a tabelas e visualizações criadas por outros sistemas, como AWS Athena ou Presto, pode ou não funcionar em Databricks Runtime ou Spark, e essas operações não são suportadas. Eles podem falhar com mensagens de erro enigmáticas. Por exemplo, acessar um view criado por Athena, Databricks Runtime ou Spark pode gerar uma exceção do tipo:
IllegalArgumentException: Can not create a Path from an empty string
Essa exceção ocorre porque o Athena e o Presto armazenam os metadados de view em um formato diferente do esperado por Databricks Runtime e Spark.