Databricks SQL notas sobre a versão 2021
A seguir, o senhor descreve as melhorias e atualizações no Databricks SQL de janeiro a dezembro de 2021.
15 de dezembro de 2021
O Databricks SQL está disponível de forma geral. Isso representa um marco importante para oferecer aos senhores a primeira plataforma lakehouse que unifica cargas de trabalho de dados, AI e BI em um só lugar. Com o GA, o senhor pode esperar o mais alto nível de estabilidade, suporte e prontidão empresarial da Databricks para cargas de trabalho de missão crítica. Leia os blogs de anúncio da GA para saber mais.
alerta agora são agendados independentemente das consultas. Quando o senhor cria um novo alerta e cria uma consulta, é solicitado a criar também um programar para o alerta. Se o senhor já tinha um alerta, duplicamos o programa da consulta original. Essa alteração também permite que o senhor defina o alerta para as consultas de execução como Owner e execução como Viewer. execução como Proprietário consulta a execução no alerta programar designado com a credencial do proprietário da consulta. execução como Viewer consulta a execução no alerta designado programar com a credencial do criador do alerta. Veja o que é Databricks SQL alerta? e programar uma consulta.
Agora o senhor pode reordenar os parâmetros no editor SQL e nos painéis.
A documentação para criar visualizações de mapas de calor foi expandida. Consulte as opções do mapa de calor.
9 de dezembro de 2021
Ao criar uma visualização de tabela, agora você pode definir a cor da fonte de uma coluna como um valor estático ou um intervalo de valores com base nos valores do campo da coluna. O valor literal é comparado ao limite. Por exemplo, para colorir os resultados cujos valores excedem
500000, crie o limite> 500000, em vez de> 500,000. Consulte Formatar condicionalmente as cores das colunas.Os ícones na guia SQL do navegador de esquemas do editor agora permitem que o senhor faça a distinção entre tabelas e visualizações.
1 de dezembro de 2021
Agora, o senhor pode aplicar os parâmetros de configuração do site SQL no nível workspace. Esses parâmetros se aplicam automaticamente a todos os pontos de extremidade existentes e novos do SQL no workspace. Consulte Configurar parâmetros SQL.
18 de novembro de 2021
Agora o senhor pode abrir o editor SQL usando um atalho na barra lateral. Para abrir o editor SQL, clique em SQL Editor.
Se o senhor tiver permissão para criar clusters de ciência de dados & engenharia, agora poderá criar o endpoint SQL clicando em Create na barra lateral e em SQL endpoint.
Os administradores agora podem transferir a propriedade de uma consulta, painel ou alerta para um usuário diferente por meio da interface do usuário. Veja:
4 de novembro de 2021
Em uma visualização de mapa (coropleta), o número máximo de etapas de gradiente para cores na legenda foi aumentado de 11 para 20. O site default tem 5 etapas de gradiente, incluindo a cor mínima e a cor máxima.
O editor da guia SQL agora oferece suporte ao gerenciamento de tab em massa. Se o senhor clicar com o botão direito do mouse em tab, verá a opção Fechar outros, Fechar à esquerda, Fechar à direita e Fechar tudo. Observe que se o senhor clicar com o botão direito do mouse no primeiro ou no último tab, não verá as opções Fechar à esquerda ou Fechar à direita.
28 de outubro de 2021
Ao acessar view uma tabela no Catalog Explorer, o senhor tem duas opções para simplificar a interação com a tabela:
Clique em Criar consulta > para criar uma consulta que selecione todas as colunas e retorne as primeiras 1000 linhas.
Clique em Create > Quick Dashboard para abrir uma página de configuração na qual o senhor pode selecionar colunas de interesse e criar um painel e consultas de suporte que forneçam algumas informações básicas usando essas colunas e apresentem parâmetros no nível do painel e outros recursos.
19 de outubro de 2021
Novos atalhos de teclado agora estão disponíveis no editor de guias:
Abrir novo tab:
Windows:
Cmd+Alt+TMac:
Cmd+Option+T
Fechar aba atual
Windows:
Cmd+Alt+WMac:
Cmd+Option+W
Abrir caixa de diálogo de consultas
Windows:
Cmd+Alt+OMac:
Cmd+Option+O
23 de setembro de 2021
Agora é possível criar um novo painel clonando um painel existente, desde que o senhor tenha as permissões CAN RUN, CAN EDIT e CAN MANAGE no painel e em todas as consultas upstream. Consulte Clonar um painel legado.
Agora você pode usar
GROUP BYem uma visualização com várias colunas do eixo Y. Consulte o gráfico de dispersão.Agora o senhor pode usar
{{ @@yPercent}}para formatar o rótulo dos dados em um gráfico de barras empilhadas não normalizado. Consulte Gráfico de barras.Se o senhor usar a autenticação SAML e sua credencial SAML expirar em alguns minutos, agora será solicitado proativamente a acessar log in novamente antes de executar uma consulta ou atualizar um painel. Isso ajuda a evitar a interrupção devido a uma credencial que expira durante a execução da consulta.
20 de setembro de 2021
Agora, o senhor pode transferir a propriedade de dashboards, consultas e alertas usando o site Permissions REST API. Consulte ACLs de consulta.
16 de setembro de 2021
Nos resultados da consulta, os resultados
BIGINTagora são serializados como strings quando maiores que 9007199254740991. Isso corrige um problema em que os resultados doBIGINTpoderiam ser truncados nos resultados da consulta. Outros resultados inteiros ainda são serializados como números. A formatação de números no rótulo do eixo e nas dicas de ferramentas não se aplica aos resultadosBIGINTque são serializados como strings. Para obter mais informações sobre tipos de dados em Databricks SQL, consulte o tipo BIGINT.
7 de setembro de 2021
A Databricks está implementando as alterações que se seguem ao longo de uma semana. Seu workspace pode não estar habilitado para essas alterações até depois de 7 de setembro.
Databricks SQL está agora em Public Preview e ativado para todos os usuários no novo espaço de trabalho.
Observação
Se o seu workspace foi habilitado para Databricks SQL durante a Public Preview - ou seja, antes da semana que começa em 7 de setembro de 2021 - os usuários mantêm o direito atribuído antes dessa data, a menos que o senhor o altere. Em outras palavras, se um usuário não teve acesso ao Databricks SQL durante a visualização pública, ele não o terá agora, a menos que um administrador o conceda.
Os administradores podem gerenciar quais usuários têm acesso ao Databricks SQL atribuindo o direito de acesso ao Databricks SQL (
databricks-sql-accessna API) a usuários ou grupos. Em default, os novos usuários têm esse direito.
Os administradores podem limitar um usuário ou grupo a acessar somente Databricks SQL e impedir que eles acessem ciência de dados & engenharia ou Databricks Mosaic AI removendo o direito de acesso ao espaço de trabalho (workspace-access no API) do usuário ou grupo. Em default, os novos usuários têm esse direito.
Importante
Para acessar log in e Databricks, o usuário deve ter o direito de acessoDatabricks SQL ou de acesso ao espaço de trabalho (ou ambos).
Um pequeno endpoint clássico SQL endpoint chamado Starter é pré-configurado em todos os espaços de trabalho, para que o senhor possa começar a criar dashboards, visualizações e consultas imediatamente. Para lidar com cargas de trabalho mais complexas, é possível aumentar facilmente seu tamanho (para reduzir a latência) ou o número de clusters subjacentes (para lidar com mais usuários concorrentes). Para gerenciar os custos, o starter endpoint está configurado para ser encerrado após 120 minutos parado.
Se o serverless compute estiver habilitado para o seu workspace e o senhor habilitar o endpoint SQL sem servidor, um SQL endpoint sem servidor chamado endpoint Starter sem servidor será criado automaticamente e o senhor poderá usá-lo para painéis, visualizações e consultas. O ponto de extremidade SQL sem servidor começa mais rapidamente do que o ponto de extremidade SQL clássico e termina automaticamente após 10 minutos parado.
Para ajudar você a começar a trabalhar rapidamente, uma nova experiência de integração guiada está disponível para administradores e usuários. O painel de integração é visível em default, e o senhor sempre pode ver quantas tarefas de integração ainda restam na barra lateral. Clique na tarefa à esquerda para reabrir o painel de integração.
O senhor pode começar a usar o Databricks SQL rapidamente com dois conjuntos de dados avançados em um catálogo somente leitura chamado
SAMPLES, que está disponível em todos os espaços de trabalho. Quando o senhor aprender sobre Databricks SQL, poderá usar esses esquemas para criar consultas, visualizações e painéis. Nenhuma configuração é necessária e todos os usuários têm acesso a esses esquemas.O esquema
nyctaxicontém dados da viagem de táxi na tabelatrips.O esquema
tpchcontém dados da receita de varejo e da cadeia de suprimentos nas tabelas a seguir:customerlineitemnationorderspartpartsuppregionsupplier
Clique em executar sua primeira consulta no painel de integração para gerar uma nova consulta do esquema
nyctaxi.Para saber mais sobre a visualização de dados no Databricks SQL sem a necessidade de configuração, o senhor pode importar painéis da Dashboard Samples Gallery. Esses painéis são alimentados pelo conjunto de dados no catálogo
SAMPLES.Para acessar view a Dashboard Samples Gallery, clique em Import sample dashboard (Importar painel de amostra ) no painel de integração.
Agora, o senhor pode criar e soltar funções nativas do SQL usando o CREATE FUNCTION e DROP FUNCTION comando.
2 de setembro de 2021
Os usuários com a permissão CAN EDIT em um dashboard agora podem gerenciar a lista de programação e inscrição do dashboard refresh. Anteriormente, era necessária a permissão CAN MANAGE. Para obter mais informações, consulte Automaticamente refresh a dashboard.
Agora o senhor pode pausar temporariamente a exportação programada para assinantes do painel sem modificar o programa. Anteriormente, o senhor tinha que remover todos os assinantes, desativar o programar e recriar. Para obter mais informações, consulte Pausar temporariamente as atualizações programadas do dashboard.
Em default, as visualizações não são mais redimensionadas dinamicamente com base no número de resultados retornados, mas mantêm a mesma altura independentemente do número de resultados. Para retornar ao comportamento anterior e configurar uma visualização para redimensionar dinamicamente, ative Redimensionar dinamicamente a altura do painel nas configurações da visualização no painel. Para obter mais informações, consulte Opções de tabela.
Se o senhor tiver acesso a mais de um workspace no mesmo account, poderá alternar o espaço de trabalho em Databricks SQL. Clique em
 no canto inferior esquerdo de seu Databricks workspace e selecione um workspace para alternar para ele.
no canto inferior esquerdo de seu Databricks workspace e selecione um workspace para alternar para ele.
30 de agosto de 2021
O endpoint SQL sem servidor fornece compute instantâneo, gerenciamento mínimo e otimização de custos para consultas SQL.
Até agora, a computação para o ponto final SQL aconteceu no plano compute em seu AWS account. A versão inicial do serverless compute adiciona o endpoint SQL sem servidor a Databricks SQL, movendo esses recursos de compute para o seu Databricks account.
O senhor usa o armazém serverless SQL com consultas Databricks SQL da mesma forma que usa o ponto de extremidade SQL que está em seu próprio AWS account, agora chamado de ponto de extremidade clássico SQL . Mas o armazém serverless SQL normalmente começa com baixa latência em comparação com o endpoint SQL clássico, é mais fácil de gerenciar e é otimizado para custo.
Antes que o senhor possa criar um depósito serverless SQL , um administrador deve habilitar a opção de endpoint SQL sem servidor para o seu workspace. Uma vez ativado, o novo ponto de extremidade SQL é sem servidor por default, mas o senhor pode continuar a criar o ponto de extremidade SQL como sem servidor ou clássico, conforme desejar.
Para obter detalhes sobre a arquitetura compute sem servidor e comparações com o plano compute clássico, consulte o plano compute sem servidor. Para obter detalhes sobre a configuração do armazém serverless SQL - incluindo como converter o ponto de extremidade clássico SQL em sem servidor - consulte Ativar o armazém serverless SQL .
Para obter a lista de regiões compatíveis com o armazém serverless SQL , consulte Databricks clouds and regions.
... importante:: a computação sem servidor está sujeita aos termos aplicáveis que devem ser aceitos por um proprietário do account ou administrador do account para habilitar o recurso.
12 de agosto de 2021
Agora o senhor pode enviar uma atualização programada do painel para endereços email que não estejam associados à conta Databricks. Ao visualizar um dashboard, clique em Scheduled (Programado ) para view ou atualizar a lista de endereços email inscritos. Se um endereço email não estiver associado a um Databricks account, ele deverá ser configurado como um destino de notificação. Para obter mais informações, consulte Automaticamente refresh a dashboard.
Agora, um administrador pode encerrar a consulta de outro usuário enquanto ela está sendo executada. Para obter mais informações, consulte Encerrar uma consulta em execução.
05 de agosto de 2021
Para reduzir a latência no endpoint SQL quando seu workspace usa AWS Glue catálogo de dados como metastore externo, agora o senhor pode configurar o cache do lado do cliente. Para obter mais informações, consulte Maior latência com o Glue Catalog do que com o Databricks Hive metastoree Configure data access properties for SQL warehouse.
Formatação aprimorada dos resultados
EXPLAINExplique que os resultados são mais fáceis de ler
Formatado como monoespaçado sem quebra de linha
29 de julho de 2021
Fazer malabarismos com várias consultas ficou mais fácil com o suporte a várias guias no editor de consultas. Para usar o editor de guias, consulte Editar várias consultas.
08 de julho de 2021
Os widgets de visualização em painéis agora têm títulos e descrições para que você possa adaptar o título e a descrição das visualizações usadas em vários painéis ao próprio painel.
A barra lateral foi atualizada para melhorar a visibilidade e a navegação:
Os armazéns agora são o endpointSQL e a história foi renomeada para Query History.
(anteriormente denominadas Usuários) foram movidas para
 a conta. Ao selecionar a conta, o senhor pode alterar o endereço Databricks workspace e log.
a conta. Ao selecionar a conta, o senhor pode alterar o endereço Databricks workspace e log.As configurações de usuário foram movidas para
 Settings e foram divididas em Settings e SQL Admin Console. O SQL Admin Console é visível apenas para administradores.
Settings e foram divididas em Settings e SQL Admin Console. O SQL Admin Console é visível apenas para administradores.O ícone de ajuda mudou para
 Ajuda.
Ajuda.
01 de julho de 2021
O novo Catalog Explorer permite que o senhor explore e gerencie facilmente as permissões em bancos de dados e tabelas. Os usuários podem view detalhes do esquema, visualizar dados de amostra e ver detalhes e propriedades da tabela. Os administradores podem view e alterar os proprietários de objetos de dados, e os proprietários de objetos de dados podem conceder e revogar permissões. Para obter detalhes, consulte O que é o Catalog Explorer?.
Os eixos Y nos gráficos horizontais foram atualizados para refletir a mesma ordem das tabelas. Se o senhor tiver selecionado anteriormente a ordem inversa, poderá usar a opção Reverse Order (Ordem inversa ) no eixo Y tab para inverter a nova ordem.
17 de junho de 2021
PhotonO novo mecanismo de execução vetorizada do Databricksestá agora ativado pelo default para o recém-criado endpoint SQL (tanto a UI quanto o REST API). O Photon acelera de forma transparente
Grava nas tabelas Parquet e Delta.
Muitas consultas SQL. Consulte Limitações.
Gerencie facilmente usuários e grupos com
CREATE GROUP,DROP GROUP,ALTER GROUP,SHOW GROUPSeSHOW USERScomandos. Para obter detalhes, consulte Declarações de segurança e Mostrar declarações.O navegador de esquemas do editor de consultas é mais rápido e rápido em esquemas com mais de 100 tabelas. Nesses esquemas, o navegador de esquemas não carregará todas as colunas automaticamente; a lista de tabelas ainda é exibida normalmente, mas as colunas são carregadas somente quando você clica em uma tabela. Essa alteração afeta o autocompletar de consultas no editor de consultas, pois ele depende dessas informações para mostrar sugestões. Até que você expanda uma tabela e carregue suas colunas, essas sugestões não estarão disponíveis.
03 de junho de 2021
Os administradores do espaço de trabalho Databricks recém-ativado agora recebem o direito Databricks SQL por default e não precisam mais conceder a si mesmos o direito de acesso Databricks SQL usando o console de administração.
Photon está agora em visualização pública e ativado por default para o novo endpointSQL .
O balanceamento de carga com vários clusters está agora em visualização pública.
Agora o senhor pode permitir a colaboração em dashboards e consultas com outros membros da sua organização usando a permissão CAN EDIT. Consulte Listas de controle de acesso.
26 de maio de 2021
SQL analítica é renomeada para Databricks SQL. Essa mudança tem os seguintes impactos voltados para o cliente:
As referências na interface do usuário da web foram atualizadas.
O direito de conceder acesso ao Databricks SQL foi renomeado:
UI: Databricks SQL access (anteriormente SQL analítica access)
API SCIM:
databricks-sql-access(anteriormentesql-analytics-access)
Os usuários, grupos e entidades de serviço com o direito anterior foram migrados para o novo direito.
As tags dos eventos de auditoria log relacionados a Databricks SQL foram alteradas:
O prefixo dos eventos Databricks SQL agora é
databrickssql.changeSqlAnalyticsAclagora échangeDatabricksSqlAcl.
Atualizações do painel
O nome do arquivo de exportação do painel foi atualizado para ser o nome do painel + timestamp, em vez de um UUID.
O limite de registros de exportação foi aumentado de 22k para 64k.
Os autores de painéis agora podem exportar periodicamente e email o Snapshot do painel. Os instantâneos do painel são extraídos do estado do painel default, o que significa que nenhuma interação com as visualizações estará presente no instantâneo.
Se o senhor for o proprietário de um painel, poderá criar um programa refresh e inscrever outros usuários, que receberão o email Snapshot do painel sempre que ele for atualizado.
Se o senhor tiver permissão view para um painel, poderá se inscrever no programa refresh existente.
Consulte Inscrição no Dashboard Snapshot.
As expressões pushdown de predicado (
StartsWith,EndsWith,Contains,Not(EqualTo())eDataType) estão desativadas para o AWS Glue Catalog, pois não são compatíveis.
13 de maio de 2021
O Databricks SQL não tenta mais adivinhar os tipos de coluna. Anteriormente, uma coluna com o formato
xxxx-yy-ddera tratada automaticamente como uma data, mesmo que fosse um código de identificação. Agora, essa coluna não é mais tratada automaticamente como uma data. Você deve especificar isso na consulta, se desejar. Essa alteração pode fazer com que algumas visualizações que dependiam do comportamento anterior não funcionem mais. Nesta versão, você pode alterar a opção > Configurações > Compatibilidade com versões anteriores para retornar ao comportamento anterior. Em uma versão futura, removeremos esse recurso.O editor de consultas agora tem um indicador de progresso da consulta. As mudanças de estado agora estão visíveis em uma barra de progresso continuamente atualizada.
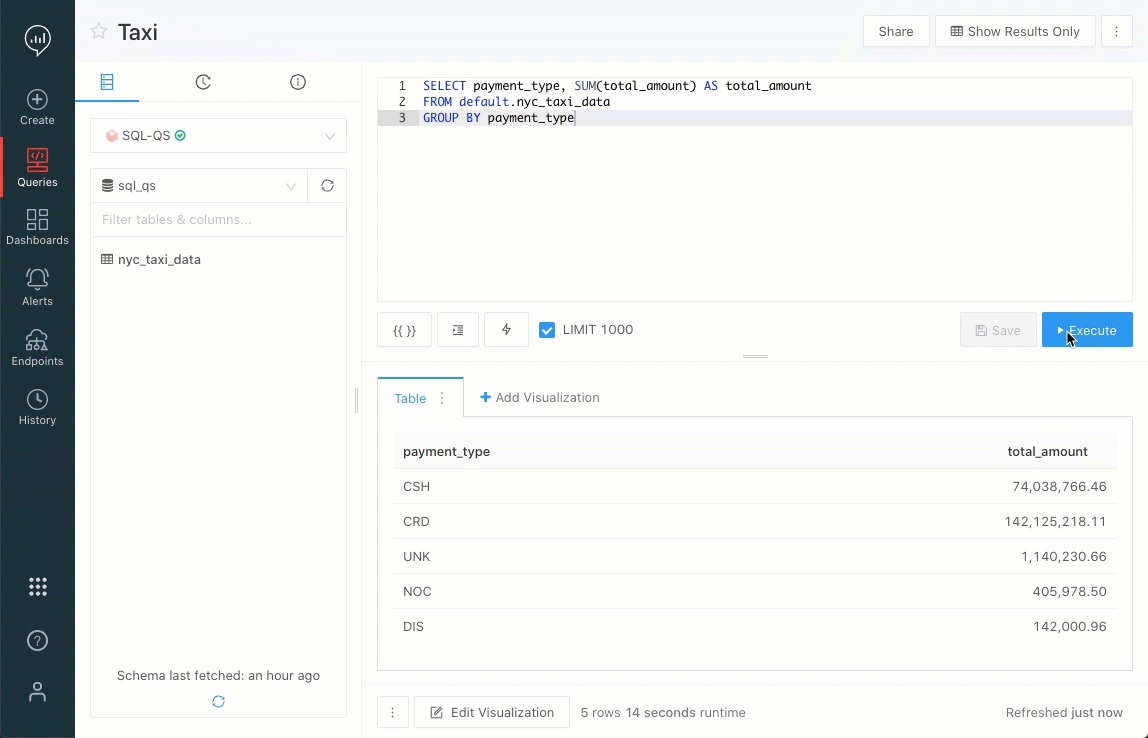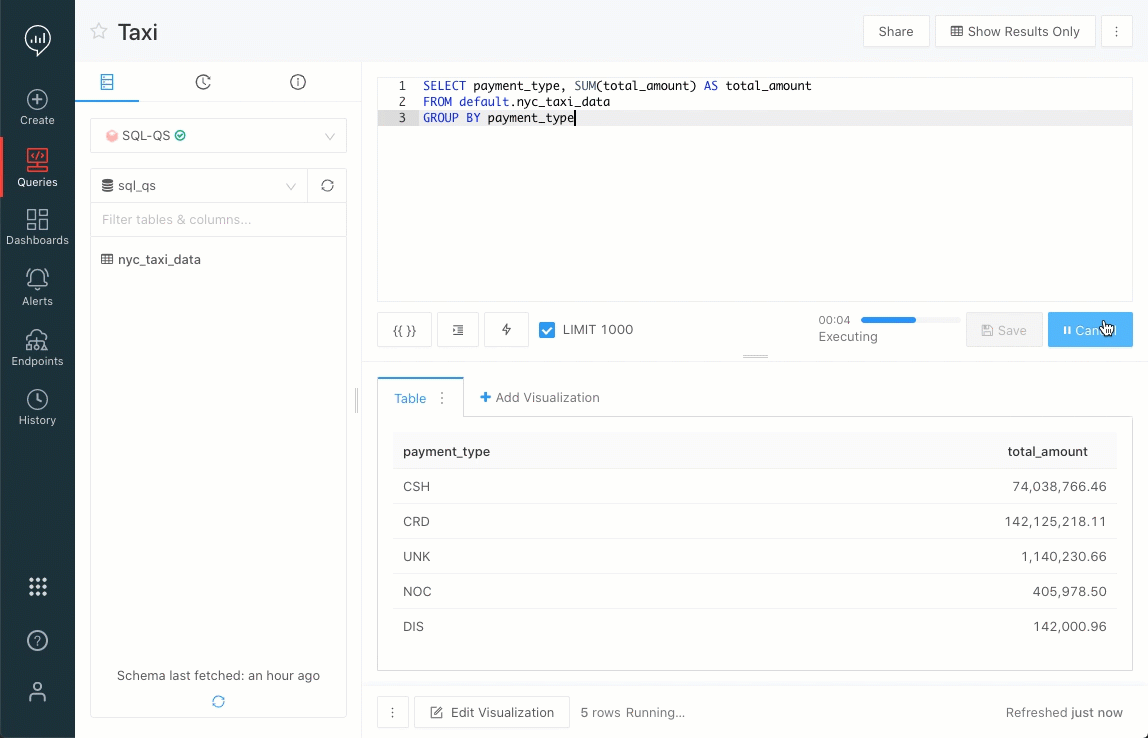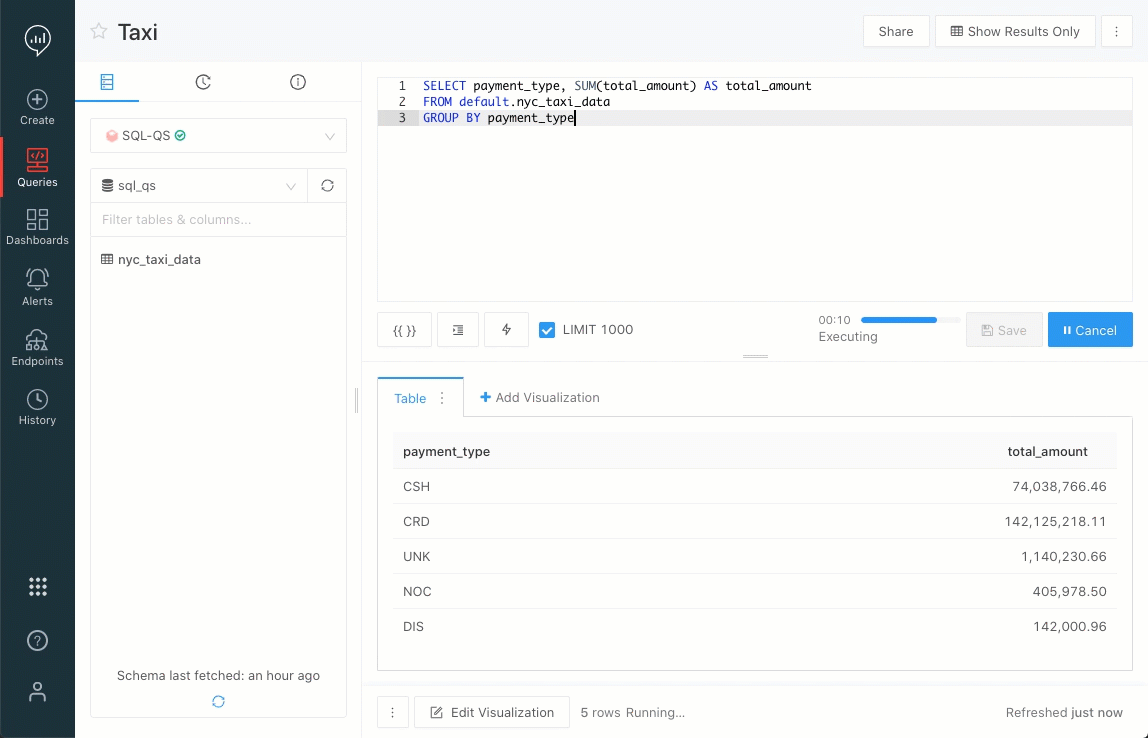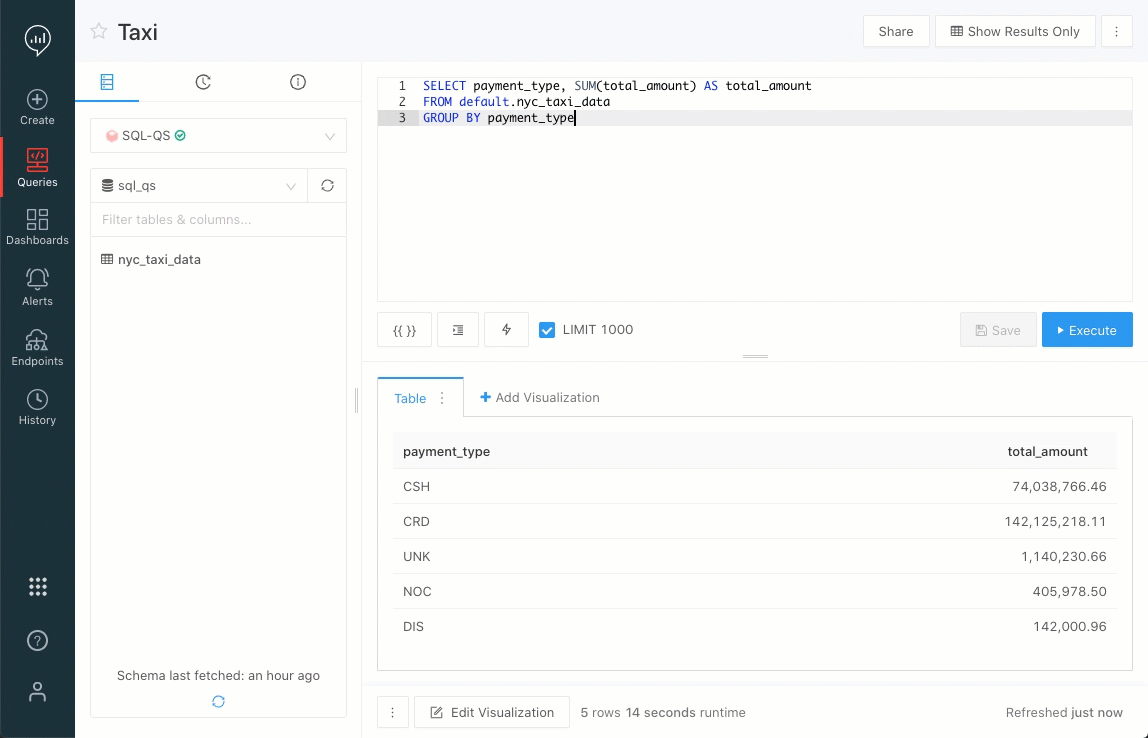
Problemas corrigidos
Editor de SQL. O editor SQL agora manterá o texto selecionado e a posição de rolagem ao alternar entre as guias de consulta.
Editor de SQL. Se o senhor clicar em "execução" em uma consulta no editor SQL, navegar para outra página e retornar enquanto a consulta ainda estiver sendo executada, o editor exibirá o estado correto da consulta. Se a consulta for concluída enquanto o senhor estiver em outra página, os resultados da consulta estarão disponíveis ao retornar à página do editor SQL.
Agora o senhor pode usar o MySQL 8.0 como um metastore externo.
DESCRIBE DETAILcomando em Delta tabelas não falham mais comjava.lang.ClassCastException: java.sql.Timestamp cannot be cast to java.time.Instant.A leitura de arquivos Parquet com
INT96timestamps não falha mais.Quando um usuário tem permissão CAN RUN em uma consulta e a executa, se a consulta foi criada por outro usuário, o histórico da consulta exibe o executor da consulta como o usuário.
Os valores nulos agora são ignorados ao renderizar um gráfico, melhorando a usabilidade dos gráficos. Por exemplo, anteriormente, as barras em um gráfico de barras pareciam muito pequenas quando valores nulos estavam presentes. Agora, os eixos são definidos com base somente em valores não nulos.