MLflow による Amazon Bedrock のトレース
MLflow は、Amazon Bedrockの自動トレースをサポートしており、高性能を提供する AWS 上の完全マネージドサービスです。
Anthropic、Cohere、Meta、Mistral AIなどの主要なAIの基盤。自動トレースを有効にする
mlflow.bedrock.autolog関数を呼び出すことでAmazon Bedrock、MLflow はLLM呼び出しのトレースをキャプチャします
をアクティブMLflowエクスペリメントに記録します。
MLflow トレースは、Amazon Bedrock 呼び出しに関する次の情報を自動的にキャプチャします。
- プロンプトと完了応答
- 待ち時間
- モデル名
- 温度、max_tokens (指定されている場合) などの追加のメタデータ。
- 応答で返された場合の関数呼び出し
- 例外が発生した場合
サーバレス コンピュート クラスターでは、自動ログは自動的に有効になりません。 この統合の自動トレースを有効にするには、明示的に mlflow.bedrock.autolog() を呼び出す必要があります。
前提 条件
Amazon BedrockでMLflow Tracingを使用するには、MLflowとPython用AWS SDK (Boto3)をインストールする必要があります。
- Development
- Production
開発環境の場合は、Databricks の追加機能と boto3を含む完全な MLflow パッケージをインストールします。
pip install --upgrade "mlflow[databricks]>=3.1" boto3
フル mlflow[databricks] パッケージには、Databricks でのローカル開発と実験のためのすべての機能が含まれています。
本番運用デプロイメントの場合は、 mlflow-tracing と boto3をインストールします。
pip install --upgrade mlflow-tracing boto3
mlflow-tracingパッケージは、本番運用での使用に最適化されています。
MLflow 3 は、Amazon Bedrock で最高のトレースエクスペリエンスを実現することを強くお勧めします。
以下の例を実行する前に、環境を構成する必要があります。
Databricks ノートブックの外部ユーザーの場合 : Databricks 環境変数を設定します。
export DATABRICKS_HOST="https://your-workspace.cloud.databricks.com"
export DATABRICKS_TOKEN="your-personal-access-token"
Databricks ノートブック内のユーザーの場合 : これらの資格情報は自動的に設定されます。
AWS 認証情報 : Bedrock アクセス用の AWS 認証情報が設定されていることを確認します。本番運用で使用する場合は、環境変数の代わりにIAM 、 AWS Secrets Manager、またはDatabricksシークレットの使用を検討してください (例: AWS CLI 、 IAM 、または環境変数の使用)。
サポートされている APIs
MLflow は、次の Amazon Bedrock APIの自動トレースをサポートしています。
基本的な例
import boto3
import mlflow
import os
# Ensure your AWS credentials are configured in your environment
# (e.g., using AWS CLI `aws configure`, or by setting
# AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY, AWS_SESSION_TOKEN, AWS_DEFAULT_REGION)
# Enable auto-tracing for Amazon Bedrock
mlflow.bedrock.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/bedrock-tracing-demo")
# Create a boto3 client for invoking the Bedrock API
bedrock = boto3.client(
service_name="bedrock-runtime",
region_name="<REPLACE_WITH_YOUR_AWS_REGION>",
)
# MLflow will log a trace for Bedrock API call
response = bedrock.converse(
modelId="anthropic.claude-3-5-sonnet-20241022-v2:0",
messages=[
{
"role": "user",
"content": "Describe the purpose of a 'hello world' program in one line.",
}
],
inferenceConfig={
"maxTokens": 512,
"temperature": 0.1,
"topP": 0.9,
},
)
エクスペリメントに関連付けられたログトレースは、 MLflow UI で確認できます。
生の入力と出力
デフォルトでMLflow は、 Chat タブの入力メッセージと出力メッセージに対して、チャットのようなリッチな UI をレンダリングします。 未加工の入力ペイロードと出力ペイロード (構成パラメーターを含む) を表示するには、UI の Inputs / Outputs タブをクリックします。
Chatパネルは、converse と converse_stream APIsでのみサポートされています。もう一方のAPIsについては、MLflowInputs / Outputsタブのみが表示されます。
ストリーミング
MLflow は、 Amazon Bedrock APIへのストリーミング呼び出しのトレースをサポートしています。 生成されたトレースでは、集約された出力メッセージが [ Chat ] タブに表示され、個々のチャンクは [ Events ] タブに表示されます。
response = bedrock.converse_stream(
modelId="anthropic.claude-3-5-sonnet-20241022-v2:0",
messages=[
{
"role": "user",
"content": [
{"text": "Describe the purpose of a 'hello world' program in one line."}
],
}
],
inferenceConfig={
"maxTokens": 300,
"temperature": 0.1,
"topP": 0.9,
},
)
for chunk in response["stream"]:
print(chunk)
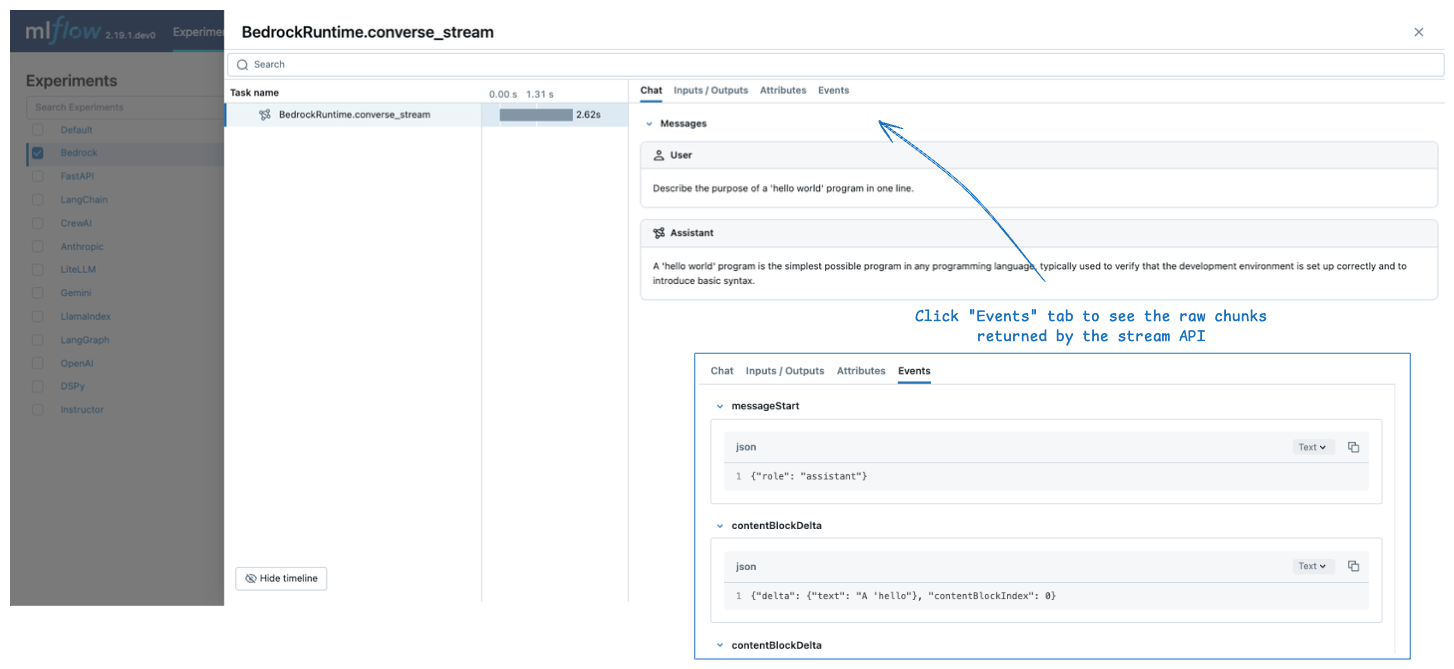
MLflow は、ストリーミング応答が返されてもすぐにはスパンを作成しません。代わりに、ストリーミング チャンクが 消費 されるときにスパンを作成します (たとえば、上記のコード スニペットの for ループ)。
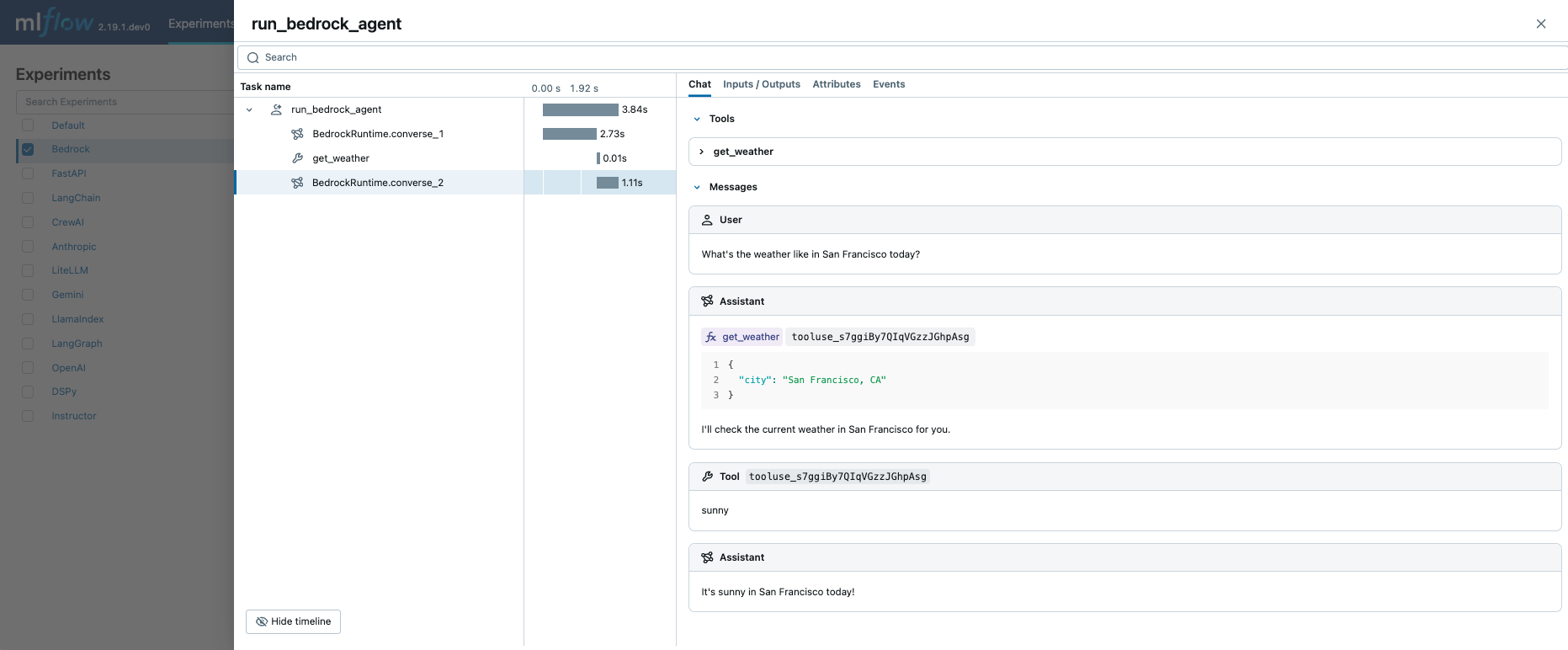
関数呼び出しエージェント
MLflow Tracing は、 Amazon Bedrock APIを呼び出すときに、関数呼び出しメタデータを自動的にキャプチャします。 レスポンスの関数定義と命令は、トレースUIの Chat タブで強調表示されます。
これを手動トレース機能と組み合わせることで、関数呼び出しエージェント (ReAct) を定義し、その実行をトレースできます。エージェントの実装全体は複雑に見えるかもしれませんが、トレースの部分は非常に簡単です: (1) トレースする関数に@mlflow.traceデコレータを追加し、(2) Amazon Bedrock の自動トレースを有効にする mlflow.bedrock.autolog()を使用します。MLflow は、呼び出しチェーンの解決や実行メタデータの記録などの複雑さを処理します。
import boto3
import mlflow
from mlflow.entities import SpanType
import os
# Ensure your AWS credentials are configured in your environment
# Enable auto-tracing for Amazon Bedrock
mlflow.bedrock.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/bedrock-agent-demo")
# Create a boto3 client for invoking the Bedrock API
bedrock = boto3.client(
service_name="bedrock-runtime",
region_name="<REPLACE_WITH_YOUR_AWS_REGION>",
)
model_id = "anthropic.claude-3-5-sonnet-20241022-v2:0"
# Define the tool function. Decorate it with `@mlflow.trace` to create a span for its execution.
@mlflow.trace(span_type=SpanType.TOOL)
def get_weather(city: str) -> str:
""" "Get the current weather in a given location"""
return "sunny" if city == "San Francisco, CA" else "unknown"
# Define the tool configuration passed to Bedrock
tools = [
{
"toolSpec": {
"name": "get_weather",
"description": "Get the current weather in a given location",
"inputSchema": {
"json": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "The city and state, e.g., San Francisco, CA",
},
},
"required": ["city"],
}
},
}
}
]
tool_functions = {"get_weather": get_weather}
# Define a simple tool calling agent
@mlflow.trace(span_type=SpanType.AGENT)
def run_tool_agent(question: str) -> str:
messages = [{"role": "user", "content": [{"text": question}]}]
# Invoke the model with the given question and available tools
response = bedrock.converse(
modelId=model_id,
messages=messages,
toolConfig={"tools": tools},
)
assistant_message = response["output"]["message"]
messages.append(assistant_message)
# If the model requests tool call(s), invoke the function with the specified arguments
tool_use = next(
(c["toolUse"] for c in assistant_message["content"] if "toolUse" in c), None
)
if tool_use:
tool_func = tool_functions[tool_use["name"]]
tool_result = tool_func(**tool_use["input"])
messages.append(
{
"role": "user",
"content": [
{
"toolResult": {
"toolUseId": tool_use["toolUseId"],
"content": [{"text": tool_result}],
}
}
],
}
)
# Send the tool results to the model and get a new response
response = bedrock.converse(
modelId=model_id,
messages=messages,
toolConfig={"tools": tools},
)
return response["output"]["message"]["content"][0]["text"]
# Run the tool calling agent
question = "What's the weather like in San Francisco today?"
answer = run_tool_agent(question)
上記のコードを実行すると、すべての LLM 呼び出しとツール呼び出しを含む 1 つのトレースが作成されます。
本番運用環境では、安全な キー管理のために、ハードコードされた値の代わりに常にAI Gateway またはDatabricks シークレット APIを使用します。
自動トレースを無効にする
Amazon Bedrock の自動トレースは、 mlflow.bedrock.autolog(disable=True) または mlflow.autolog(disable=True)を呼び出すことでグローバルに無効にできます。